[toc]

1 PostgreSQL的体系结构
PostgreSQL数据库由连接管理系统(系统控制器)、编译执行系统、存储管理系统、事务系统、系统表五大部分组成
- 连接管理系统接受外部操作对系统的请求,对操作请求进行预处理和分发,起系统逻辑控制作用
- 编译执行系统由查询编译器、查询执行器组成,完成操作请求在数据库中的分析处理和转化工作,最终实现物理存储介质中数据的操作
- 存储管理系统由索引管理器、内存管理器、外存管理器组成,负责存储和管理物理数据,提供对编译查询系统的支持;
- 事务系统囱事务管理器、日志管理器、并发控制、锁管理器组成,日志管理器和事务管理器完成对操作请求处理的事务一致性支持,锁管理器和并发控制提供对并发访问数据的一致性支持
- 系统表是 PostgreSQL 数据库的元信息管理中心,包括数据库对象信息和数据库管理控制信息,系统表管理元数据信息,将 PostgreSQL 数据库的各个模块有机地连接在一起,形成个高效的数据管理系统。
2 PostgreSQL的查询编译阶段中的遗传算法
查询处理器是数据库管理系统中的一个部件集合,它允许用户使用 SQL 语言在较高层次上表达查询,其主要职责是将用户的各种命令转化成数据库上的操作序列并执行。查询处理分查询编译和查询执行两个阶段。
当PostgreSQL 的后台服务进程接收到查询语句后,首先将其传递到查询分析模块,进行词法、语法和语义分析 若是简单的命令(例如建表、创建用户、备份等)则将其分配到功能性命令处理模块;
对于复杂的命令( SELECT/INSERT/DELETEl UPDA四)则要为其构建查询树( Query 结构体) .然后交给查询重写模块。查询重写模块接收到查询树后,按照该查询所涉及的规则和视图对查询树进行重写,生成新的查询树。
生成路径模块依据重写过的查询树,考虑关系的访问方式、连接方式和连接顺序等问题,采用动态规划算法或遗传算法,生成最优的表连接路径 最后,由最优路径生成可执行的计划,并将其传递到查询执行模块执行。
因此PG中的遗传算法的使用主要在生成最优的表链接路径上
3 查询规划的总体流程
查询规划的最终目的是得到可被执行器执行的最优计划,整个过程可分为预处理、生成路径和生成计划三个阶段。
- 预处理实际上是对查询树( Query 结构体)的进一步改造,这种改造可通过 SQL语句体现。在此过程中,最重要的是提升子链接和提升子查询。
- 在生成路径阶段,接收到改造后的查询树后,采用动态规划算法或遗传算法,生成最优连接路径和候选的路径链表。
- 在生成计划阶段,用得到的最优路径 首先生成基本计划树,然后添加 GROUPBY HAVING ORDER BY 子句所对应的计划节点形成 整计划树
4 路径生成算法
路径代表了对一个表或者多个表中数据的访问方式。
由于单个表的访问方式(顺序访问、索引访问)、两个表间的连接方式(嵌套循环连接、归并连接、 Hash 连接)以及多个表间的连接顺序(左连接、右连接和布希连接)都有多种,因此访问 表或多个袤的路径也会有多种,
每个路径都可能是上述访问方式、连接方式和连接顺序的一种组合。查询执行模块只需要执行效率最高的路径。因此在准备计划时,查询规划器需要考虑所有的路径,并从中挑选出最优的路径来生成执行计划,这个生成并挑选最优路径的工作由路径生成算法完成
PostgreSQL 中有两种路径生成算法:动态规划算法和遗传算法。
动态规划算法是生成路径的默认算法,但在某些情况下,检查一个查询所有可能的路径会花去很多的时间和内存空间,特别是所要执行的查询涉及大量的关系的时候。在这种情况下,为了在合理的时间里判断一个合理的执行计划, PostgreSQ 将使用遗传算法生成路径。
是否启用遗传算法由两个因素决定:
- 在系统配置中是否允许使用遗传算法:由全局变量enable_geqo控制,其值来自于配置文件中的 geqo 配置项,默认情况下是允许。
- 需要连接的基本关系是否超过使用遗传算法的阈值:由全局变量geqo_threshold 控制,其值来自于配置文件中的geqo_threshold配置选项,
默认值是 12 ,即参加连续的基本关系数大于或等于 12 时就会采用遗传算法来生成路径
5 遗传算法概述
遗传算法 (GA) 是一种种启发式的优化方法 (heuristic optimization method) ,它通过既定的随机搜索进行操作。
优化问题的可能解的集合被认为是个体(individuals)组成的种群(population).一个个体对它的环境的适应程度由它的适应值(fitness) 。一个个体在搜索空间里的参照物是用染色体(chromosomes)表示的,实际上这是一套字符串。一个基因(gene)是染色体的一个片段,基因是被优化的单个参数的编码。对一个基因的典型的编码 以是二进制 (binary)或整数(integer)。通过仿真进化过程的重组(recombination)、变异(mutation) 和选择(selection )找到新一代的搜索点,它们的平均适应值要比它们的祖先好。
在PostgreSQL中,遗传算法将路径作为个体,将个体以某种方式编码(个体体现了连接顺序),然后通过重组得到后代,考虑连接代价来计算后代的适应值,再选择合适的后代进行下一次迭代。当到达一定的迭代次数之后,遗传算法终止。选择遗传算法可以减少生成路径的时间,但是遗传算法并不一定能找到"最好"的规划,它只能找到相对较优的路径。
6 PostgreSQL中的遗传算法
PostgreSQ 中,遗传算法主要用在连接路径的生成操作中,其流程如下:
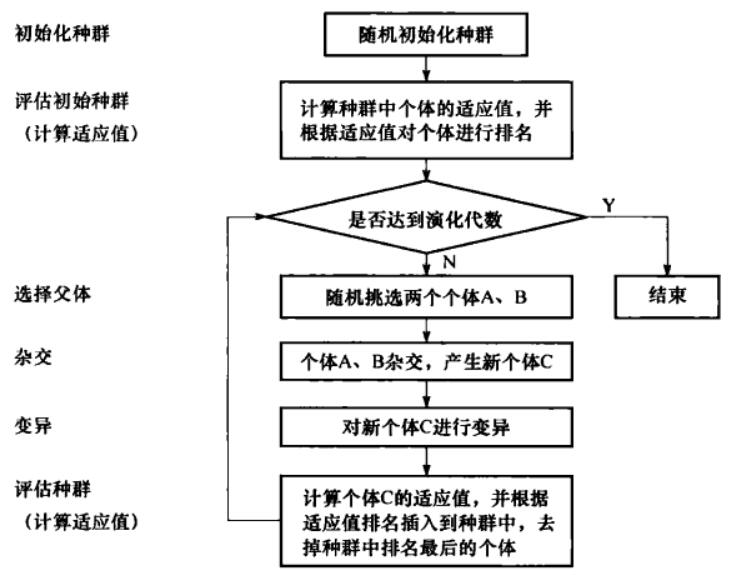
(1)个体编码方式及种群初始化
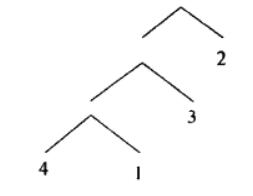
PG中用遗传算法解决表连接的问题的方式类似于TSP问题。可能的连接路径被当作整数串进行编码。v每个穿代表查询中的一种可能的连接顺序。
如下图的查询书可以用整数串"4132"编码,即首先连接表"4"和"1" 得到的结果表再和表 “3” 连接,最后再和"2" 连接。
遗传算法执行第一步为随机初始化种群。假设种群大小为n,首先随机初始化n个排列树,每一个排列数即是一个个体。然后基于n各排列数生成的基本表的连接路径,在此过程中进行代价评估,将最后的代价作为适应值衡量该个体的优劣。
每一个个体都用Chromosome结构表示,记录了个体的排列和代价
typedef int Gene;
typedef struct Chromosome{
Gene *string;//染色体的数据值
Cost worth;//对染色体的代价评估
}//Chromosome
(2)适应值
个体的适应值等于该个体中N个表的连接代价。适应值计算由geqo_eval实现,包括以下步骤:
- 检查个体的有效性
- 确定个体的连接次序以及连接方式
- 计算个体的适应值
计算个体的适应值时.首先要检查个体是否有效。也就是说,对一个给定的个体,能不能把这个个体中的表按照某种次序连接起来,因为有些表之间是不能连接的。如果一个个体按任何次序都不能连接,那么这么个体是无效的。对于有效的个体,还要确定连续次序和连接方式。在连接次序和连接方式确定之后才能计算个体的
(3)父体选择策略
附体选择策略是基于排名的选择策略,选择概率函数如下公式。
其中max是个体总数,bias默认值是2.0,geo_rand是0.0~1.0之间的随机数,f(geo_rand)表示当前个体在种群中的编号(该编号是根据当前个体的适应值在种群中的排名来确定)。
该函数表明,排名越前的个体被选择的概率越大。
(4)杂交算子
PostgreSQL 中的遗传算法提供 边重组杂交、部分匹配杂交、循环杂交、基于位置的杂交和顺序杂交等多种杂交算子,用于从父辈种群中产生新的后代个体,默认使用的是边重组杂交算法
a 边重组杂交
边重组杂交算子自函数gimme_edge_table和gimme_tour实现。函数 gimme_edge_table 用来计算边关系;函数 gimme_tour由边关系得到后代。
边重组杂交过程如下:
- 两个父体中的基因构成循环队列

- 确定父体间的边关系
在步骤1中的循环队列中,任意一个基因和相邻的基因构成“边关系”。如果某“边关系”同时在父体1和父体2中出现,则称为“共享边”。 - 由边关系得到后代
边重组杂交的基本思想是:随机地选择一个基因作为起始点,顺着它的边关系找到下一
个基因(优先考虑共享边) ,再顺着找到的基因的边关系找到第三个基因,直到找到的基因能够构成一个个体为止,最后将找到的基因按找到的顺序组成一个个体即可。
b 部分匹配杂交
由函数pmx实现,该函数流程如下:
- 在字串上均匀随机地选择两点,由这两点确定的子串称为映射段,定义两个整型变量left和right(left< right) 表示选取的映射段的起始边界。
- 用父体2的映射段替换父体1的映射段产生原始后代。
- 确定两映射段之间的映射关系
- 根据映射关系将后代合法化
c 循环杂交
循环杂交算子由函数 cx 实现,该方法从一个双亲中取一些基因,而其他的基因则取自另外一个双亲。
该方法首先随机确定一个初始位置,作为当前位置,把父体1当前位置下的基因(即编
号)赋值给当前位置下的子代,并标记此基因已被使用 然后推进当前位置到父体2当前位置(未修改前的位置)下的基因在父体1中的位置,同样把父体1当前位置下的基因赋值给当前位置下的子代。
同理推进当前位置,生成子代的基因片段,直到循环到初始位置下父体1的基因与父体2中的当前位置下的基因一样时循环结束。如果循环结束后仍有部分基因没有被使用,则将父体2中的这些基因按在父体2中存在的位置赋值到子代中同样位置。
d 基于位置的杂交
基于位置的杂交算子由函数 px 实现,该函数的处理流程如下:
- 根据基因数目 gene ,首先随机选择一个区间[gene/3 , 2/3 * gene ]中的整数p,从父体1中随机选择p个基因,设为集合A
- 对于在A中的基因,从父体1拷贝到后代中对应的位置上。
- 不在A中的基因,按它们在父体2中的顺序拷贝到后代剩余的位置上。
e 顺序杂交ox1
顺序杂交算子有两种:OX1和OX1。OX1算子由函数 ox1 实现,函数 oxl 的处理流程如下:
- 从第一个父体中随机选择一个子串。
- 将子串复制到一个空串的相应位置,产生一个原始后代。
- 删去第二个父体中子串已有的基因,得到原始后代需要的其他基因的顺序。
- 按照这个基因顺序,从左到右将这些基因复制到后代的空缺位置上。
f 顺序杂交ox2
OX2 算子由函数ox2实现,其处理流程如下:
- 根据基因的数目 gene ,随机选择一个 [gene/3 , 2/3 * gene] 之间的整数 ,从父体1中随机选择p个基因,设为集合A
- 对于父体2中不在A中基因,拷贝到后代对应的位置中。
- 对在A中的基因,按它们在父体 中的顺序依次拷贝到后代剩余的位中。
(5)变异算子
变异算子由函数geqo_mutation实现,该函数随机地从父体中产生两个变异位,交换这两个变异位的数值,执行num_gene(基因数目)次这样的操作。
(6)终止条件
遗传算法采用设定演化代数的方法,但演化到一定数量的代数时,就停止演化。默认的演化代数是种群的大小(pool_size ,缓冲池的大小)。演化代数的计算涉及下面两个参数:
- geqo_effort :整型变量,是用于限制种群大小的影响因子。取值范围是 [1 10 ],默认值为5
- geqo_pool_size :整型变量 ,表示缓冲池(用于存储种群中的个体)大小.缓冲池的大小和种群大小相同, 其值至少为2
种群大小(缓冲池的大小) pool_size 由函数伊gimme_pool_size 确定,其参数 nr_rel 为查询中表的数量。计算方法如下:
- 计算上限值 maxsize和下限值minsize
- 计算基准大小
- 如果基准大小位于上限值和下限值之间,则取基准大小作为种群大小;如果低于下限值,则取下限值;如果高于上限值,则取上限值
(7)基于排列生成路径
在遗传算法中由排列生成连接路径由以下算法实现

其中变量rels中保存了按照排列数所对应的各个基本关系(即基本表)。
变量rels_temp用来保存当前不可连接的关系。(不可连接指只能用笛卡尔积进行连接)
该算法的处理过程:
依次取rels中的所有基本表,在rels_temp中依次寻找可以与其连接的表,如果存在可连接的表,则把这两个表进行连接生成新的表,并从头开始继续在rels_temp中寻找可连接的表,并将其与新生成的表连接,一直到找不到可连接的表位置,最后将最终生成的新表插入rels_temp结尾;继续在rels中取下一个表,重复上述过程。
7 源码分析
源码目录分析
access文件夹包含各种存储访问方法、索引的实现。(重要)
bootstrap文件夹为数据库初始化时调用方法。
catalog文件夹为系统目录。
commands文件夹为SQL命令。(重要)
executor文件夹为执行器相关代码。(重要)
foreign文件夹为FDW相关代码,使得用户可以通过SQL访问没有存储在数据库中的数据。(扩展)
jit文件夹为Just-In-Time Compilation,为即时编译的相关代码,用于提高查询语句性能。(扩展)
lib文件夹为通用函数。
libpq文件夹为c/cpp的库函数,处理与客户端的通信。
main文件夹为主程序。
nodes文件夹为链表、节点等数据结构,以及相关的方法。(重要)
optimizer文件夹为优化器相关代码。(重要)
parser文件夹为编译器相关代码。(重要)
partitioning文件夹为分片相关代码。(重要)
po文件夹为语言文件配置。
port文件夹为平台兼容性处理相关代码。
postmaster文件夹为postmaster进程,以及相关辅助进程的代码。
regex文件夹为正则处理相关代码。(重要)
replication文件夹为有关流复制的相关代码。(重要)
rewrite文件夹为规则与视图相关的重写处理。
snowball文件夹为全文检索相关(语干处理)代码。
statisics文件夹为收集统计信息相关代码,与估算相关。
storage文件夹为管理各种类型存储系统相关代码。(重要)
tcop文件夹为postgres服务进程的主要处理部分,即查询流程调用的相关代码。(重要)
tsearch文件夹为全文检索。(扩展)
utils文件夹为各种支持函数,如错误报告、各种初始化操作、内存管理等。
我的分析任务:PG中遗传算法的使用分析
在文件src/backend/optimizer/geqo中为遗传优化计划器
src/backend/optimizer目录分析
该目录下的文件使用解析器返回的查询结构,生成执行器使用的计划。
/plan目录生成实际的输出计划
/path目录生成所有可能的连接表的方法
/geqo目录下位单独的“遗传优化”计划器
/prep目录处理特殊情况下的预处理步骤
/util目录下为公用的模块
geqo下的代码具体分析
(1) geqo_main.c
其中共有三个函数
-
RelOptInfo * geqo(PlannerInfo *root, int number_of_rels, List *initial_rels)
该函数为遗传算法优化的主函数,通过调用该函数来用遗传算法生成查询计划。
该函数有三个参数root:PlannerInfo 结构体包含有关正在优化的查询的各种信息,包括涉及的表、连接条件以及可能相关的任何约束或索引。遗传算法使用此信息生成潜在查询计划并评估其适合度。number_of_rels:这个整数表示正在优化的关系数,即查询中涉及的表数。initial_rels:这是一个 RelOptInfos 的 List,表示正在优化的初始关系。
函数返回一个指向 RelOptInfo 结构体的指针,该结构体表示遗传算法找到的最佳查询计划。
随后该函数依次完成:
初始化数据;获得随机数种子;设置GA相关参数;为缓冲池分配空间;随机初始化缓冲池;并按适应值对缓冲池中的个体进行排序;为重组杂交进行空间分配;进行遗传算的迭代,依次进行选择重组变异;选择最优个体;释放空间;返回最优个体。
该函数为遗传算法的主要部分,main函数。
static int gimme_pool_size(int nr_rel)
该函数用于确定缓冲池大小(种群大小)static int gimme_number_generations(int pool_size)
从该函数得到迭代次数
(2) geqo_misc.c
该文件下函数主要进行调试使用,对算法中间的结果进行输出
static double avg_pool(Pool *pool)
返回平均代价值void print_pool(FILE *fp, Pool *pool, int start, int stop)
输出当前种群中所有个体的染色体和代价void print_gen(FILE *fp, Pool *pool, int generation)
输出某一代基因的最好,最坏,中位数和平均代价值void print_edge_table(FILE *fp, Edge *edge_table, int num_gene)
输出边重组杂交的边表
(3) geqo_mutation.c
只有一个函数,对种群中的个体实施变异操作
void geqo_mutation(PlannerInfo *root, Gene *tour, int num_gene)
(4) geqo_pool.c
该文件中包含与缓冲区的相关函数
Pool * alloc_pool(PlannerInfo *root, int pool_size, int string_length)
为遗传算法缓冲器分配空间void free_pool(PlannerInfo *root, Pool *pool)
释放1函数中分配的空间voidrandom_init_pool(PlannerInfo *root, Pool *pool)
随机初始化缓冲池void sort_pool(PlannerInfo *root, Pool *pool)
从小到大按适应度排序缓冲池中的个体static int compare(const void *arg1, const void *arg2)
排序的方法,源码中使用快速排序算法Chromosome * alloc_chromo(PlannerInfo *root, int string_length)
为个体分配空间void free_chromo(PlannerInfo *root, Chromosome *chromo)
释放为个体分配的空间void spread_chromo(PlannerInfo *root, Chromosome *chromo, Pool *pool)
插入一个新的个体到缓冲池中,代替缓冲池中的最差的个体
(5) geqo_random.c
该文件用来产生随机数,含有三个函数
void geqo_set_seed(PlannerInfo *root, double seed)
设置GEQO随机数生成器的种子,以确保每次运行GEQO时使用相同的随机数序列double geqo_rand(PlannerInfo *root)
函数使用了简单的线性同余算法来生成伪随机数。该函数返回一个范围在 0 到 1 之间的双精度浮点数int geqo_randint(PlannerInfo *root, int upper, int lower)
函数的作用是生成一个介于 upper 和 lower 之间的随机整数。
(6) geqo_selection.c
该文件内进行父体选择
static int linear_rand(PlannerInfo *root, int pool_size, double bias)
该函数实现线性随机选择算法,使用了类似于概率密度函数的方法,其中偏差参数用于增加某些候选项被选择的概率,用于选择父代来产生后代。void geqo_selection(PlannerInfo *root, Chromosome *momma, Chromosome *daddy,Pool *pool, double bias)
该函数使用随机选择过程来选择两个父染色体进行交叉。
(7) geqo_copy.c
该文件内只有一个函数void geqo_copy(PlannerInfo *root, Chromosome *chromo1, Chromosome *chromo2,int string_length),用来复制个体
(8) 几个杂交算子文件
- geqo_cx.c 循环杂交
包含函数int cx(PlannerInfo *root, Gene *tour1, Gene *tour2, Gene *offspring,int num_gene, City * city_table) - geqo_erx.c 边重组杂交,包含以下函数
Edge * alloc_edge_table(PlannerInfo *root, int num_gene)为边表分配空间void free_edge_table(PlannerInfo *root, Edge *edge_table)释放边表空间float gimme_edge_table(PlannerInfo *root, Gene *tour1, Gene *tour2, int num_gene, Edge *edge_table)填充记录两个个体间的边的数据结构static int gimme_edge(PlannerInfo *root, Gene gene1, Gene gene2, Edge *edge_table)从给定基因中构建一条边并将其加入边表int gimme_tour(PlannerInfo *root, Edge *edge_table, Gene *new_gene, int num_gene)通过边表和基因返回一条可行的路径长度static void remove_gene(PlannerInfo *root, Gene gene, Edge edge, Edge *edge_table)从边表中移除该基因static Gene gimme_gene(PlannerInfo *root, Edge edge, Edge *edge_table)从给定的边表中返回一个基因static Gene edge_failure(PlannerInfo *root, Gene *gene, int index, Edge *edge_table, int num_gene)当遇到失败的边缘时,对基因进行修复
- geqo_pmx.c 部分匹配杂交
包含函数void pmx(PlannerInfo *root, Gene *tour1, Gene *tour2, Gene *offspring, int num_gene) - geqo_ox1.c 顺序杂交1
void ox1(PlannerInfo *root, Gene *tour1, Gene *tour2, Gene *offspring, int num_gene,City * city_table) - geqo_ox1.c 顺序杂交2
voidox2(PlannerInfo *root, Gene *tour1, Gene *tour2, Gene *offspring, int num_gene, City * city_table) - geqo_px.c 基于位置的杂交
void px(PlannerInfo *root, Gene *tour1, Gene *tour2, Gene *offspring, int num_gene,City * city_table)
(9) geqo_eval.c
该文件对查询树进行估价
Cost geqo_eval(PlannerInfo *root, Gene *tour, int num_gene)
返回一个个体的查询树的代价RelOptInfo * gimme_tree(PlannerInfo *root, Gene *tour, int num_gene)接收一个查询优化器(PlannerInfo)的指针和一组遗传算法的基因(Gene),然后返回一个查询优化树(RelOptInfo)。static List * merge_clump(PlannerInfo *root, List *clumps, Clump *new_clump, int num_gene,bool force)作用是合并一个新的数据块(new_clump)到一个包含多个数据块的列表中(clumps),并返回合并后的列表。参数 num_gene 表示数据块中基因的数量,而参数 force 用于控制是否强制进行合并。static bool desirable_join(PlannerInfo *root,RelOptInfo *outer_rel, RelOptInfo *inner_rel)用于确定是否应该对两个关系进行连接,这两个关系分别由 outer_rel 和 inner_rel 表示,其确定连接是否可行是基于多个因素,如连接的预估成本和选择性等
(10) geqo_recombination.c
该文件为杂交重组程序,包含以下函数
void init_tour(PlannerInfo *root, Gene *tour, int num_gene)随机生成一条合法的“旅行推销员”路径(即每个点仅访问一次)City * alloc_city_table(PlannerInfo *root, int num_gene)为城市表分配内存void free_city_table(PlannerInfo *root, City * city_table)为城市表回收内存
8 总结
本次数据库实验我主要对PostgreSQL源码中的遗传算法部分进行了分析,分析了源码中该部分的具体函数,并了解了遗传算法在PG中的工作流程,如果之后有空,希望能研习全部的PG源码。
源码中遗传算法用于寻找最优的生成路径,这一点与TSP问题相似。
当点数过多时,使用动态规划难以求出最优解,这时就可以使用遗传算法较快地求出较优解来生成路径,提升了查询编译地速度。