
8 复用
8.1 组合语法
- 组合:将对象引用放入新类中即可
- 初始化引用有以下4中方式
-
- 在定义时立刻初始化
-
- 在类的构造器中
-
- 在对象实际使用之前
-
- 使用实例初始化
-
class Soap {
private String s;
Soap() {//2 构造器初始化
System.out.println("Soap()");
s = "Constructed";
}
@Override public String toString() { return s; }
}
public class Bath {
private String // 1. 立即初始化
s1 = "Happy",
s2 = "Happy",
s3, s4;
private Soap castile;
private int i;
private float toy;
public Bath() {
System.out.println("Inside Bath()");
s3 = "Joy";
toy = 3.14f;
castile = new Soap();
}
// 实例初始化
{ i = 47; }
@Override public String toString() {
if(s4 == null) // 延迟初始化
s4 = "Joy";
return
"s1 = " + s1 + "\n" +
"s2 = " + s2 + "\n" +
"s3 = " + s3 + "\n" +
"s4 = " + s4 + "\n" +
"i = " + i + "\n" +
"toy = " + toy + "\n" +
"castile = " + castile;
}
public static void main(String[] args) {
Bath b = new Bath();
System.out.println(b);
}
}
/* Output:
Inside Bath()
Soap()
s1 = Happy
s2 = Happy
s3 = Joy
s4 = Joy
i = 47
toy = 3.14
castile = Constructed
*/
8.2 继承语法
- 创建一个类时,如无指定继承对象,将会隐式继承标准根类Object
- Java只允许单继承
- 继承通过关键字
extends后跟基类实现,此时自动获得基类的所有字段和方法 - 通过
super关键字,来指代当前类继承的"基类"的
初始化基类
-
对于子类和基类,当创建子类对象时,其里面包含了一个基类的
子对象(subobject),该子对象等同于直接创建基类对象,只是该对象被包括在子对象中 -
Java会自动在子类构造其中插入对基类构造器的调用
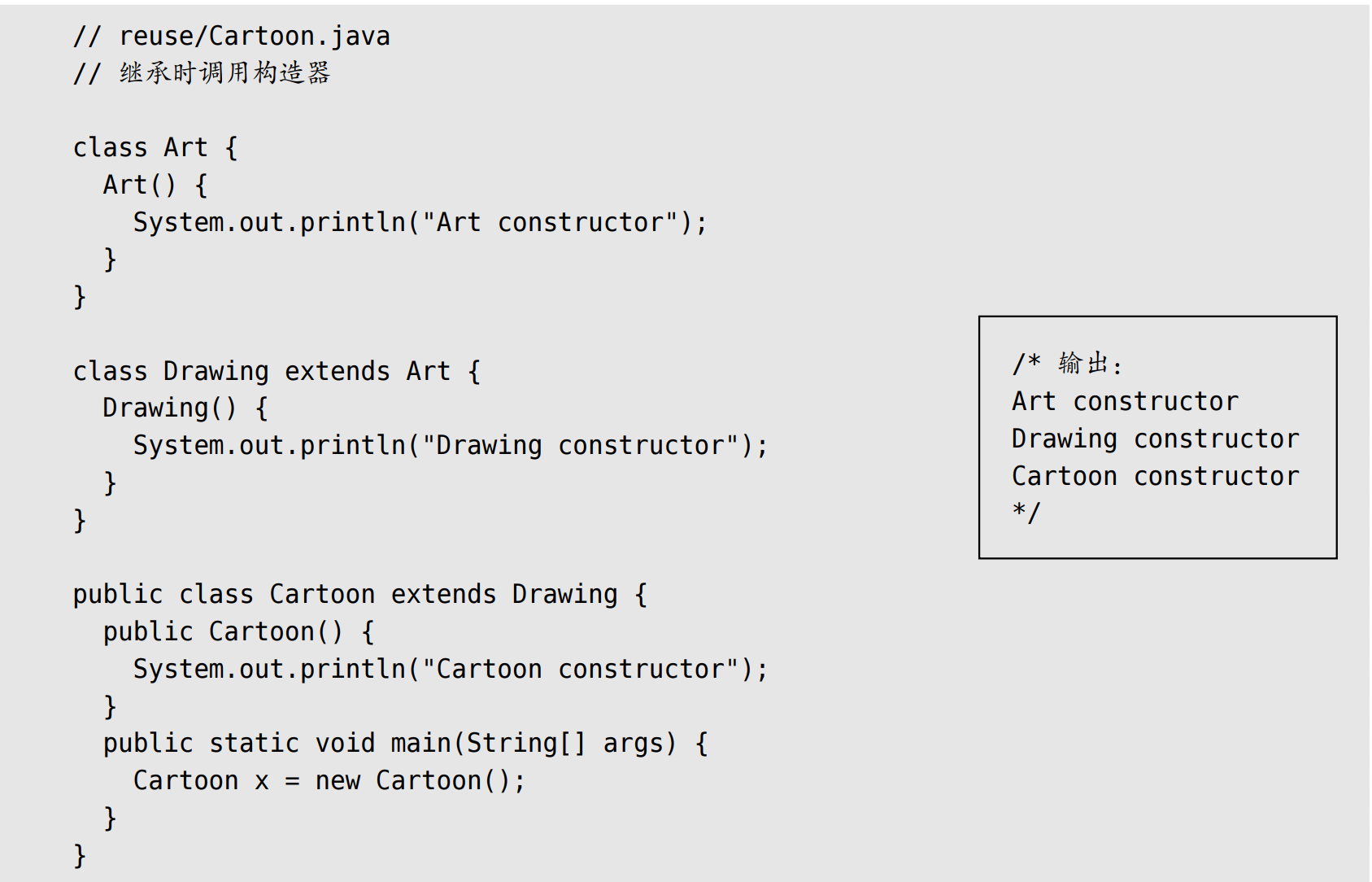
-
对于带参的构造器,需要使用super关键字和对应的参数列表,来显式的调用基类构造器,否则编译报错

8.3 委托
-
第三种关系
委托(delegation),介于继承和组合之间- 将成员对象放在构建的类中(类似组合),但同时在新类中公开了成员对象的所有方法(类似继承)
-
例子:对于一艘太空船需要一个控制模块,这里使用继承方法,但逻辑上讲不通,而组合方法中,不能通过太空船直接掉用到控制模块的方法,此时可以使用委托
-
这里相当于方法调用被转发到了内部的controls对象,这里的接口与继承得到的接口相同
- 但是,这里可以更好的控制委托,因为这里可以选择仅提供成员对象的部分方法,比如控制模块的一些不能暴露给飞船控制人员的方法
public class SpaceShipDelegation {
private String name;
private SpaceShipControls controls =
new SpaceShipControls();
public SpaceShipDelegation(String name) {
this.name = name;
}
// Delegated methods 委托方法:
public void back(int velocity) {
controls.back(velocity);
}
public void down(int velocity) {
controls.down(velocity);
}
public void forward(int velocity) {
controls.forward(velocity);
}
public void left(int velocity) {
controls.left(velocity);
}
public void right(int velocity) {
controls.right(velocity);
}
public void turboBoost() {
controls.turboBoost();
}
public void up(int velocity) {
controls.up(velocity);
}
public static void main(String[] args) {
SpaceShipDelegation protector =
new SpaceShipDelegation("NSEA Protector");
protector.forward(100);
}
}
8.4 组合与继承相结合
8.4.1 确保正确的清理
- Java中没有C++中析构函数的概念,析构函数会在对象被销毁时自动调用,而Java中有GC,会在需要时回收内存
- 然而,类可能需要自己执行一些清理活动,因为你不知道GC什么时候被调用,所以此时必须明确地编写一个特殊的方法来实现
- 该方法与构造器方法类似,需要显式的声明,顺序与构造器顺序相反
package reuse;
class Shape {
Shape(int i) {
System.out.println("Shape constructor");
}
void dispose() {
System.out.println("Shape dispose");
}
}
class Circle extends Shape {
Circle(int i) {
super(i);
System.out.println("Drawing Circle");
}
@Override void dispose() {
System.out.println("Erasing Circle");
super.dispose();
}
}
class Triangle extends Shape {
Triangle(int i) {
super(i);
System.out.println("Drawing Triangle");
}
@Override void dispose() {
System.out.println("Erasing Triangle");
super.dispose();
}
}
class Line extends Shape {
private int start, end;
Line(int start, int end) {
super(start);
this.start = start;
this.end = end;
System.out.println(
"Drawing Line: " + start + ", " + end);
}
@Override void dispose() {
System.out.println(
"Erasing Line: " + start + ", " + end);
super.dispose();
}
}
public class CADSystem extends Shape {
private Circle c;
private Triangle t;
private Line[] lines = new Line[3];
public CADSystem(int i) {
super(i + 1);
for(int j = 0; j < lines.length; j++)
lines[j] = new Line(j, j*j);
c = new Circle(1);
t = new Triangle(1);
System.out.println("Combined constructor");
}
@Override public void dispose() {
System.out.println("CADSystem.dispose()");
// The order of cleanup is the reverse
// of the order of initialization:
t.dispose();
c.dispose();
for(int i = lines.length - 1; i >= 0; i--)
lines[i].dispose();
super.dispose();
}
public static void main(String[] args) {
CADSystem x = new CADSystem(47);
try {
// Code and exception handling...
} finally {
x.dispose();
}
}
}
/* Output:
Shape constructor
Shape constructor
Drawing Line: 0, 0
Shape constructor
Drawing Line: 1, 1
Shape constructor
Drawing Line: 2, 4
Shape constructor
Drawing Circle
Shape constructor
Drawing Triangle
Combined constructor
CADSystem.dispose()
Erasing Triangle
Shape dispose
Erasing Circle
Shape dispose
Erasing Line: 2, 4
Shape dispose
Erasing Line: 1, 1
Shape dispose
Erasing Line: 0, 0
Shape dispose
Shape dispose
*/
8.4.2 名称隐藏
- 如果Java基类的方法名称被多次重载,则在子类中重新定义该方法名称不会隐藏任何基类版本.无论方法实在子类还是基类中定义,重载都有效
- 即基类的方法名重载后,子类中依然可以进行方法名重载,均可以使用
class Homer {
char doh(char c) {
System.out.println("doh(char)");
return 'd';
}
float doh(float f) {
System.out.println("doh(float)");
return 1.0f;
}
}
class Milhouse {}
class Bart extends Homer {
void doh(Milhouse m) {
System.out.println("doh(Milhouse)");
}
/*
以下这种写法是错的,不是重写函数而是正常的同一函数名不同参数的重载函数,本质是同名的不同函数,相当于在子类中新造乐一个函数
@Override void doh(Milhouse m) {
System.out.println("doh(Milhouse)");
}
*/
}
public class Hide {
public static void main(String[] args) {
Bart b = new Bart();
b.doh(1);
b.doh('x');
b.doh(1.0f);
b.doh(new Milhouse());
}
}
/* Output:
doh(float)
doh(char)
doh(float)
doh(Milhouse)
*/
8.5 选择组合还是继承
-
组合和继承都会将对象放在新类中(组合是显式执行,继承是隐式执行)
-
新类中使用现有类的功能而不是接口时,使用组合,即在心累中嵌入一个对象来实现自己的特性(多是private),新类的用户看到的是新类的定义而不是嵌入对象的接口.
- 又是组合的成员对象也可以为public(类似一种半委托)
-
当使用继承时,通过现有的类生成一个特殊版本,意味着对通用类进行定制.
-
继承是"is-a"关系,组合是"has-a"关系
8.6 protected关键字
- protected:包访问权限和子类访问权限
class Villain {
private String name;
protected void set(String nm) { name = nm; }
Villain(String name) { this.name = name; }
@Override public String toString() {
return "I'm a Villain and my name is " + name;
}
}
public class Orc extends Villain {
private int orcNumber;
public Orc(String name, int orcNumber) {
super(name);
this.orcNumber = orcNumber;
}
public void change(String name, int orcNumber) {
set(name); // 这里change函数可以调用set,因为set是protected型的
this.orcNumber = orcNumber;
}
@Override public String toString() {
return "Orc " + orcNumber + ": " + super.toString();
}
public static void main(String[] args) {
Orc orc = new Orc("Limburger", 12);
System.out.println(orc);
orc.change("Bob", 19);
System.out.println(orc);
}
}
/* Output:
Orc 12: I'm a Villain and my name is Limburger
Orc 19: I'm a Villain and my name is Bob
*/
8.7 向上转型
- 继承最重要的是可以表达新类和基类的关系:新类是现有类的一种类型
- 这种描述可以直接由语言支持,如下面的例子,乐器类Instrument为基类,Wind为子类,乐器类有一个play方法,那么Wind乐器也会有,即Wind乐器是一种乐器
- 以下代码中,tune()方法接受一个Instrument引用,当传入一个Wind引用时,实际Wind类就是一种Instrument类,而且tune()方法调用的Instrument对象的所有属性和方法Wind均具有.因此代码可以正常运行.这种将子类引用转换为基类引用的行为称为向上转型(upcasting)
class Instrument {
public void play() {}
static void tune(Instrument i) {
// ...
i.play();
}
}
// Wind 对象也是 instrument,因为它们有相同的接口:
public class Wind extends Instrument {
public static void main(String[] args) {
Wind flute = new Wind();
Instrument.tune(flute); // 向上转型
}
}
- 确定使用继承或组合的方法:新类是否要向上转型到基类
8.8 final关键字
- final:表示无法更改的
- 使用final出于两个原因:设计或效率,这两个原因差距很大,因此final可能被误用
8.8.1 final 数据
-
许多编程语言有常量的定义,标识某个数据是恒定的,有以下两个原因
-
- 它是一个永远不会改变的编译时常量:编译器可以将常量值"折叠"在计算中,即计算在编译时进行,节省运行开销.Java中使用final进行修饰,一个既是static也是final字段指挥分配一块不能改变的存储空间
-
- 它可以使在运行时初始化的值,而你不希望被更改
-
-
final对于基本类型,使得其值更定不变;
-
对于对象引用,final使得引用恒定不变,一旦引用被初始化一个对象,它就不能再指其它对象了,但对象本身是可以修改的.
- Java没有提供使对象恒定不变的方法,但用户可以自己编写类实现
- 空白final: 指没有初始化的final字段,编译器会保证在使用该字段前初始化该final字段
- final参数: 传递给方法的参数可以声明为final,这意味着你无法在方法中更改参数引用所指向的对象
8.8.2 final 方法
- 使用final方法的原因
-
- 把方法锁定,以防任何继承类修改它的含义
-
- 效率:编译器在遇到final方法调用时会转为内嵌调用(inline call),因此final方法调用的效率更高
- 具体:编译器会将final方法的代码复制到调用该方法的地方,而不是进行一次方法调用
-
8.8.3 final 类
- final类不能被继承,没有类可以继承final类的任何特性
- 原因:
-
- 设计:类的创建者不希望有人继承它
-
- 安全:不希望其有子类,因为它的行为可能会被子类修改,而这可能会破坏原来的类
-
8.9 初始化和类的加载
- 运行Java代码时,首先会加载类;加载类时,会先加载其基类,然后才是自身,即从根基类开始加载
- 首先加载静态变量
- 然后是静态代码块
- 创建对象时,也会从根基类开始创建,然后到自身
- 首先创建实例变量(非静态)
- 然后是执行实例代码块
- 调用构造函数进行对象的初始化
9 多态
- 跟随 数据抽象,继承,多态是面向对象编程语言的第三个基本特征
9.1 再论向上转型
- 例子:乐器类Instrument为基类,Wind为子类,乐器类有一个play方法,那么Wind乐器也会有,即Wind乐器是一种乐器
- 以下代码中,tune()方法接受一个Instrument引用,当传入一个Wind引用时,实际Wind类就是一种Instrument类,而且tune()方法调用的Instrument对象的所有属性和方法Wind均具有.因此代码可以正常运行.这种将子类引用转换为基类引用的行为称为向上转型(upcasting)
class Instrument {
public void play(Note n) {
System.out.println("Instrument.play()");
}
}
// Wind 对象也是 instrument,因为它们有相同的接口:
public class Wind extends Instrument {
// 重新定义接口方法:
@Override public void play(Note n) {
System.out.println("Wind.play() " + n);
}
public static void main(String[] args) {
Wind flute = new Wind();
Instrument.tune(flute); // 向上转型
}
}
public class Music {
public static void tune(Instrument i) {
// ...
i.play(Note.MIDDLE_C);
}
public static void main(String[] args) {
Wind flute = new Wind();
tune(flute); // 向上转型
}
}
- 如果有多个继承类,编写一个以基类为参数的方法,而不用担心特定子类,即忘记子类,只与基类的代码打交道,这正是多态实现的目标
9.2 难点
- 在mucis.java中 Music.tune()方法接受一个Instrument引用,但是传入的是Wind引用,这是如何实现的呢?
- 此时需要了解绑定这个主题
9.2.1 方法调用绑定
- 绑定:将一个方法调用和一个方法体实现关联起来称为绑定
- 前期绑定:在程序运行之前执行绑定(编译器和连接程序都可以执行前期绑定,因此有时也称为静态绑定)
- 面向过程语言中,大多数方法调用都是前期绑定
- 后期绑定(也称动态绑定,运行时绑定):在运行时根据对象的类型进行绑定
- 多态的实现就是后期绑定
- Java的所有方法都是后期绑定的,除非明确指定final,static或private
9.2.2 产生正确的行为
- 例子:Instrument类中的play()方法,在Wind类中被覆盖,当调用tune()方法时,传入的是Wind引用,但是调用的是Instrument类中的play()方法,这是如何实现的呢?
-
- 传入Wind引用时,会将Wind引用向上转型为Instrument引用
-
- 调用Instrument类中的play()方法,此时会调用Wind类中的play()方法,因为Wind类中覆盖了Instrument类中的play()方法
-
- 由于是后期绑定,因此会调用Wind类中的play()方法,而不是Instrument类中的play()方法
-
9.2.3 可扩展性
- 例子:如果需要添加一个新的乐器,只需要继承Instrument类,并覆盖play()方法即可,不需要修改任何其他代码,即tune方法的参数一直是Instrument类,但是传入的是新的乐器引用,此时调用的是新乐器的play()方法,这就是多态的可扩展性
9.2.4 陷阱:"重写"private方法

- private 方法为隐式的final,不能被覆盖,此时子类中的方法即为一个新的方法,因此子类中的方法和基类中的方法没有任何关系,此时调用的是基类中的方法
- 如果在子类中使用@Override注解,编译器会报错
9.2.5 陷阱:字段和静态方法
- 只用普通的方法调用可以是多态的,但是字段和静态方法不行
- 如果直接访问一个字段,该访问会在编译时解析
- 静态方法与类相关联,而不是与单个的对象相关联
9.3 构造器和多态
9.3.1 构造器的调用顺序
- 调用子类构造器,此时会递归调用子类的基类构造器,直到调用根基类构造器
- 如果没有在子类构造器代码中显式调用基类构造器,则会隐式的调用基类的无参构造器
- 一个复杂对象构造器的调用顺序
-
- 调用基类构造器,此时会递归调用基类的基类构造器,直到调用根基类构造器.根类先被构造,随后到子类
-
- 按声明顺序初始化成员
-
- 调用子类构造器的主体
-
9.3.2 继承与清理
- 通常由gc进行清理,如有自己清理的必要,需要自行创建dispose函数,并在子类中覆盖该函数,在子类中调用基类的dispose函数
- 清理的顺序是从子类到根基类
9.3.3 构造器内部的多态方法的行为
-
普通方法中,动态绑定调用在运行时解析
-
过早其中中调用动态绑定方法,会调用该方法被重写后的定义,但被重写的方法可能会使用到子类中的成员变量,此时子类的成员变量还未被初始化,因此会出现错误
-
编写构造器的准则:
- 用尽可能少的操作使对象进入正常状态
- 如果可以的话,避免调用其他方法,只有基类中final,private方法可以在构造器中被安全调用
9.4 协变返回类型
- Java5中添加了 协变返回类型(covariant return type)重写方法时,返回类型可以是基类方法返回类型的子类型
- 例子:process的返回类型:在WheatMill中process函数返回的是Wheat类型,而在Mill中返回的是Grain类型,此时Wheat是Grain的子类,因此可以使用协变返回类型
class Grain {
@Override public String toString() {
return "Grain";
}
}
class Wheat extends Grain {
@Override public String toString() {
return "Wheat";
}
}
class Mill {
Grain process() { return new Grain(); }
}
class WheatMill extends Mill {
@Override Wheat process() {
return new Wheat();
}
}
9.5 用继承进行设计
- 设计准则:使用继承表达行为间的差异,使用字段表达状态上的变化
9.5.1 替换和扩展
-
纯粹的"is-a"关系,子类的接口与基类相同,但可以进行重写.例子:
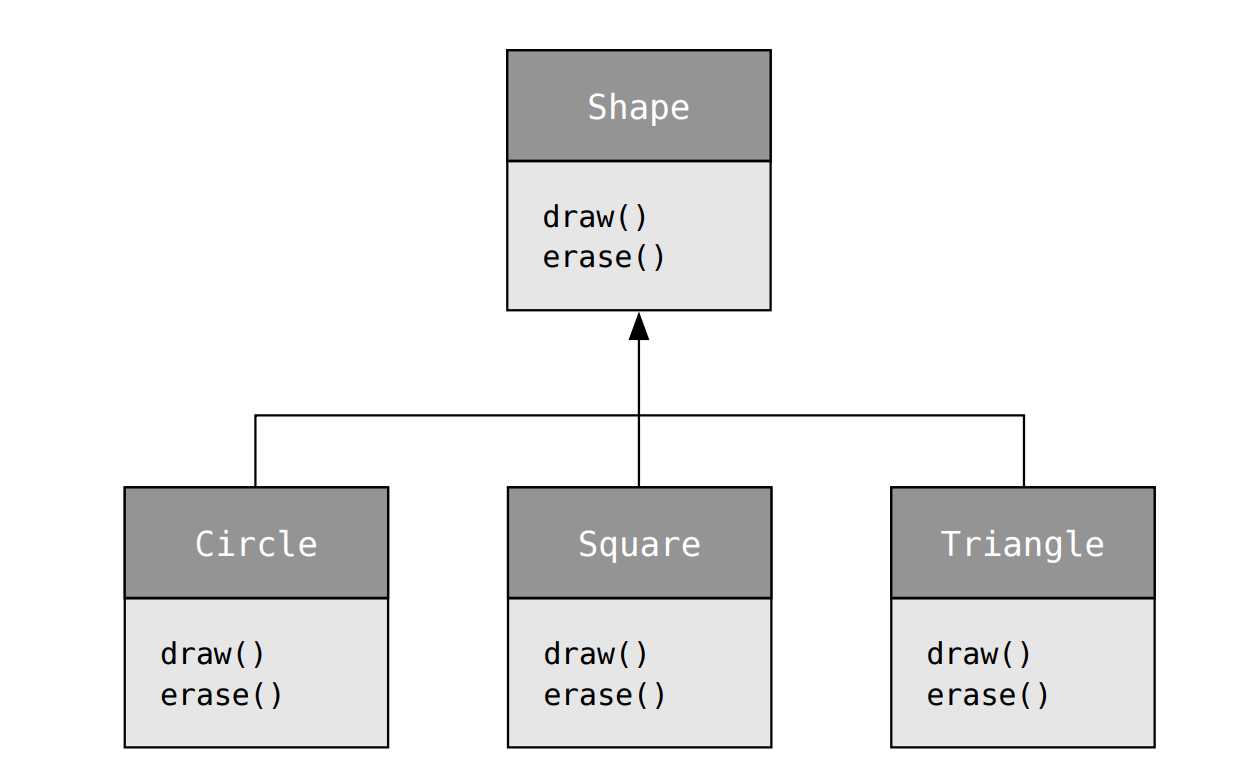
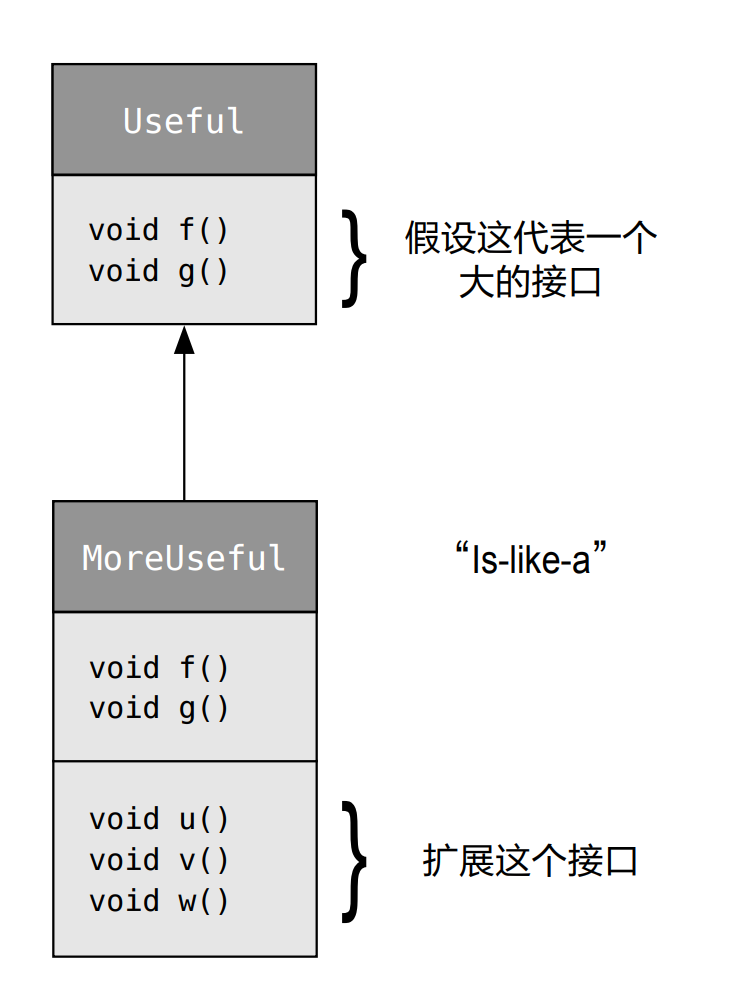
-
"is-like-a"关系,子类的接口比基类更丰富,向上转型后,无法调用子类的新的方法.例子:
9.5.2 向下转型和反射
-
向上转型会丢失特定类型的信息,自然可以通过向下转型重新获取类型信息
-
向上转型总是安全的,因为基类不可能会比有更多的接口,基类接口发送的信息子类总能接收,向下转型非也
-
某些语言(如C++)要执行特殊操作才能获得类型安全的向下转型,Java中每个转型都会被检查,如果转型是不合法的,则会抛出ClassCastException异常,这种运行时检查的行为是Java反射的一部分,例子:
class Useful {
public void f() {}
public void g() {}
}
class MoreUseful extends Useful {
@Override public void f() {}
@Override public void g() {}
public void u() {}
public void v() {}
public void w() {}
}
public class Reflect {
public static void main(String[] args) {
Useful[] x = {
new Useful(),
new MoreUseful()
};
x[0].f();
x[1].g();
// 编译时错误:无法在 Useful 中发现方法 :
//- x[1].u();
((MoreUseful)x[1]).u(); // 向下转型 / 反射
((MoreUseful)x[0]).u(); // 抛出异常
}
}
10 接口
10.1 抽象类和抽象方法
-
抽象类:介于普通类和接口之间的类,抽象类不能被实例化,只能被继承,抽象类中可以包含抽象方法,也可以没有,抽象方法只有声明,没有实现,抽象方法必须被子类实现
-
例子:Instrument可以称为抽象类,为所有的子类创建了一个共同的接口,但是Instrument类本身不能被实例化,因为它是抽象的,而且Instrument类中的play方法是抽象的,因此必须被子类实现
abstract class Instrument {
private int i;
public abstract void play(Note n);
public String what() { return "Instrument"; }
public abstract void adjust();
}
- 可实例化类继承抽象类后,要为所有的抽象方法提供定义
abstract class Uninstantiable {
abstract void f();
abstract int g();
}
public class Instantiable extends Uninstantiable {
@Override void f() { System.out.println("f()"); }//@Override表示重写了基类的方法,如果该注解,其实编译器会自动判断抽象方法是否已经被实现,所以可以去掉
@Override int g() { return 22; }
public static void main(String[] args) {
Uninstantiable ui = new Instantiable();ui.f();
}
}
-
接口只允许有public方法,抽象类对访问权限没有限制(private方法除外,因为无法被继承)
-
抽象类和抽象方法很有用
- 明确了类的抽象性,告诉用户和编译器自己的预期用途
- 有用的重构工具,让你轻松地将公共方法上移至抽象基类中,以便于在继承类中重用
10.2 接口定义
-
interface关键字创建一个完全抽象的类,不代表任何实现,接口描述了一个类应该是什么样子和做什么的,而不是如何做.其确定了方法名,参数列表和返回类型,但不提供方法主体.
-
接口允许默认方法和静态方法,可以包含字段(隐式static和final)
-
接口和抽象类显著的区别是两者的惯用方式:
- 接口通常暗示"类的类型",作为形容词使用,如Comparable接口
- 抽象类通常表示"类的成员",作为名词使用,如AbstractList类
-
创建接口使用interface关键字,前面可以加public或默认包访问权限
-
创建符合接口的类,使用implements关键字,一个类可以实现多个接口,接口中的方法必须被实现,否则编译报错.同时方法默认为public,同时实现类中的方法也必须为public,加上@Override注解可以检查是否正确重写了接口中的方法
interface Concept { // 包访问
void idea1();
void idea2();
}
class Implementation implements Concept {
@Override public void idea1() {
System.out.println("idea1");
}
@Override public void idea2() {
System.out.println("idea2");
}
}
10.2.1 默认方法
- 接口中,允许使用default关键字创建一个方法体,实现该接口的类可以在不定义方法的情况下直接替换为该默认方法体
interface InterfaceWithDefault {
void firstMethod();
void secondMethod();
default void newMethod() {
System.out.println("newMethod");
}
}
public class Implementation2
implements InterfaceWithDefault {
@Override public void firstMethod() {
System.out.println("firstMethod");
}
@Override public void secondMethod() {
System.out.println("secondMethod");
}
public static void main(String[] args) {
InterfaceWithDefault i = new Implementation2();
i.firstMethod();
i.secondMethod();
i.newMethod();
}
}
- 添加默认方法的原因:允许向现有接口中添加方法,而不会破坏已经在使用该接口的所有代码
- 默认方法也称 防御方法 或 虚拟扩展方法
10.2.2 多重继承
- Java是严格的单继承语言,只能继承一个类(或抽象类)
- 但接口有多重继承的一些特性,即一个类可以实现多个接口,这样就可以实现多重继承的效果,只要所有基类方法都有不同的名称和参数列表,代码就能正常工作,否则会报错
- 如果两个接口中有相同的方法,可以通过在实现类中重写该方法来解决
interface Jim1 {
default void jim() {
System.out.println("Jim1::jim");
}
}
interface Jim2 {
default void jim() {
System.out.println("Jim2::jim");
}
}
public class Jim implements Jim1, Jim2 {
@Override public void jim() {
Jim2.super.jim();
}
public static void main(String[] args) {
new Jim().jim();
}
}
10.2.3 接口中的静态方法
- Java8允许在接口中包含静态方法,允许在接口里包含逻辑上属于它的实用程序
- 如 runOps()这种操作该接口的方法
- show()通用工具
public interface Operation {
void execute();
static void runOps(Operation... ops) {
for(Operation op : ops)
op.execute();
}
static void show(String msg) {
System.out.println(msg);
}
}
class Heat implements Operation {
@Override public void execute() {
Operation.show("Heat");
}
}
public class MetalWork {
public static void main(String[] args) {
// 必须在静态上下文中定义才能使用方法引用
Operation twist = new Operation() {
public void execute() {
Operation.show("Twist");
}
};
Operation.runOps(
new Heat(), // [1] 常规类 Heat
new Operation() { // [2] 匿名内部类
public void execute() {
Operation.show("Hammer");
}
},
twist::execute, // [3] 方法引用
() -> Operation.show("Anneal") // [4] Lambda表达式
);
}
}
10.3 抽象类和接口
| 特性 | 接口 | 抽象类 |
|---|---|---|
| 组合 | 可以在新类中组合多个接口 | 只能继承一个抽象类 |
| 状态 | 不能包含字段(静态字段除外,但它们不支持对象状态) | 可以包含字段,非抽象方法可以引用这些字段 |
| 默认方法和抽象方法 | 默认方法不需要在子类型里实现,它只能引用接口里的方法(字段不行) | 抽象方法必须在子类型中实现 |
| 构造器 | 不能有构造器 | 可以有构造器 |
| 访问权限控制 | 隐式的public | 可以为protected或包访问权限 |
- 在合理的范围内尽可能抽象.因此二者相比更偏向使用接口.大多数情况下,常规类就能解决问题
10.4 完全解耦
-
方法与类配合使用时,只能使用该类或其子类;与接口配合时,可以使用任何实现了该接口的类
-
接口的一个重要特性是,它们与实现部分完全解耦,即使只修改接口,也不会影响现有的实现部分,因此接口是代码演化的关键
-
例子:Processor接口,可以被任何Processor实现类使用,而不需要知道Processor实现类的具体细节,只需要知道Processor实现类的接口即可,同时其他实现类也可以使用Processor接口,这就是完全解耦的好处
interface Processor {
String name();
Object process(Object input);
}
class Upcase implements Processor {
@Override public String name() { return getClass().getSimpleName(); }
@Override public String process(Object input) {
return ((String)input).toUpperCase();
}
}
class Downcase implements Processor {
@Override public String name() { return getClass().getSimpleName(); }
@Override public String process(Object input) {
return ((String)input).toLowerCase();
}
}
class Splitter implements Processor {
@Override public String name() { return getClass().getSimpleName(); }
@Override public String process(Object input) {
return Arrays.toString(((String)input).split(" "));
}
}
public class Apply {
public static void process(Processor p, Object s) {
System.out.println("Using Processor " + p.name());
System.out.println(p.process(s));
}
public static String s =
"Disagreement with beliefs is by definition incorrect";
public static void main(String[] args) {
process(new Upcase(), s);
process(new Downcase(), s);
process(new Splitter(), s);
}
}
class FilterAdapter implements Processor {
Filter filter;
FilterAdapter(Filter filter) {
this.filter = filter;
}
@Override
public String name() { return filter.name(); }
@Override
public Waveform process(Object input) {
return filter.process((Waveform)input);
}
}
10.5 组合多个接口
- Java中,一个实现类只能继承自一个类,但可以继承自多个接口;代码中先使用extend关键字,再使用implements关键字
interface CanFight {
void fight();
}
interface CanSwim {
void swim();
}
interface CanFly {
void fly();
}
class ActionCharacter {
public void fight() {}
}
class Hero extends ActionCharacter
implements CanFight, CanSwim, CanFly {
@Override public void swim() {}
@Override public void fly() {}
//CanFight中的fight()方法已经在ActionCharacter中实现,因此Hero中不需要重写
}
public class Adventure {
public static void t(CanFight x) { x.fight(); }
public static void u(CanSwim x) { x.swim(); }
public static void v(CanFly x) { x.fly(); }
public static void w(ActionCharacter x) { x.fight(); }
public static void main(String[] args) {
Hero h = new Hero();
t(h); // 当作一个 CanFight 类型
u(h); // 当作一个 CanSwim 类型
v(h); // 当作一个 CanFly 类型
w(h); // 当作一个 ActionCharacter 类型
}
}
-
使用接口的核心原因
- 向上转型为多个基类型,以及由此带来的灵活性
- 防止客户端程序员创建该类的对象,并确保该类的实现己经具备了某些特定的行为
-
使用接口还是抽象类?
- 如果要创建不带任何方法定义和成员变量的基类,那么就应该选择接口而不是抽象类
10.6 通过继承扩展接口
- 可以使用继承向接口里添加新的方法声明,也可以将多个接口组合成一个新接口
interface Monster {
void menace();
}
interface DangerousMonster extends Monster {
void destroy();
}
interface Lethal {
void kill();
}
interface Vampire extends DangerousMonster, Lethal {
void drinkBlood();
}
- 当接口组合在一起时,应避免使用相同的方法名,否则会出现歧义
10.7 适配接口
- 接口的常见用途:策略设计模式
-
- 编写一个执行某些操作的方法,该方法指定某些接口作为参数
-
- 该方法可以操作任何对象,只要该对象遵循我的接口
-
- 例子:Scanner类的构造器接受一个Readable接口作为参数,因此只要你创建的新类实现Readable接口,就可以将该类的对象传递给Scanner类的构造器
import java.nio.*;
import java.util.*;
public class RandomStrings implements Readable {
private static Random rand = new Random(47);
private static final char[] CAPITALS = "ABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray();
private static final char[] LOWERS = "abcdefghijklmnopqrstuvwxyz".toCharArray();
private static final char[] VOWELS = "aeiou".toCharArray();
private int count;
public RandomStrings(int count) {this.count = count;}
@Override public int read(CharBuffer cb) {
if(count-- == 0)
return -1; // 表示输入已经结束
cb.append(CAPITALS[rand.nextInt(CAPITALS.length)]);
for(int i = 0; i < 4; i++) {
cb.append(VOWELS[rand.nextInt(VOWELS.length)]);
cb.append(LOWERS[rand.nextInt(LOWERS.length)]);
}
cb.append(" ");
return 10; // 添加的字符串
}
public static void main(String[] args) {
Scanner s = new Scanner(new RandomStrings(10));
while(s.hasNext()) System.out.println(s.next());
}
}
- 任何类都可以实现接口,因此可以使用适配器模式,将接口与你想要的任何类结合起来,适配器中的代码将接受你所拥有的接口,并产生你所需要的接口
10.8 接口中的字段
- 接口中的字段默认为static和final,因此接口中的字段必须被初始化,且不能被修改,因此接口是一种很好的创建常量的方法,Java5之后有enum,因此不需要使用接口来创建常量
- Java里具有常量初始值的 static final 字段的命名全部使用大写字母(用下划线分割单个标识符中的多个单词)
10.9 嵌套接口
- 接口可以嵌套在类和其它接口中,嵌套在类中的接口自动是public和static的,嵌套在接口中的接口自动是public的
class A {
interface B {
void f();
}
public class BImp implements B {
@Override public void f() {}
}
public class BImp2 implements B {
@Override public void f() {}
}
public interface C {
void f();
}
class CImp implements C {
@Override public void f() {}
}
private class CImp2 implements C {
@Override public void f() {}
}
private interface D {
void f();
}
private class DImp implements D {
@Override public void f() {}
}
public class DImp2 implements D {
@Override public void f() {}
}
public D getD() { return new DImp2(); }
private D dRef;
public void receiveD(D d) {
dRef = d;
dRef.f();
}
}
interface E {
interface G {
void f();
}
// 1. 多余的 "public",接口中的都是 public 的
public interface H {
void f();
}
void g();
// 2. 接口中不能使用private
//- private interface I {}
}
public class NestingInterfaces {
public class BImp implements A.B {
@Override public void f() {}
}
class CImp implements A.C {
@Override public void f() {}
}
// 3. private 接口只能在定义的类中实现
//- class DImp implements A.D {
//- public void f() {}
//- }
class EImp implements E {
@Override public void g() {}
}
class EGImp implements E.G {
@Override public void f() {}
}
class EImp2 implements E {
@Override public void g() {}
class EG implements E.G {
@Override public void f() {}
}
}
public static void main(String[] args) {
A a = new A();
// 4. A.D 为A的私有接口,除了A之外,没有人能实现A.D接口:
//- A.D ad = a.getD();
// 5. 只能返回A.D的引用,而且只能在A中使用:
//- A.DImp2 di2 = a.getD();
// 6. 无法访问该接口的方法
//- a.getD().f();
// 7. 只有另一个A才能接收处理A.D
A a2 = new A();
a2.receiveD(a.getD());
}
}
- 这些特性初步看是为了语法一致性,但之后肯定是有新的用法
10.10 接口和工厂
- 工厂方法设计模式:在接口中提供一个创建对象的方法,让实现类决定实例化对象的类型
- 这样代码和接口实现完全隔离,可以透明地将某个实现替换为另一个实现
- 例子:
interface Service {
void method1();
void method2();
}
interface ServiceFactory {
Service getService();
}
class Service1 implements Service {
Service1() {} // Package access
@Override public void method1() {
System.out.println("Service1 method1");
}
@Override public void method2() {
System.out.println("Service1 method2");
}
}
class Service1Factory implements ServiceFactory {
@Override public Service getService() {
return new Service1();
}
}
class Service2 implements Service {
Service2() {} // Package access
@Override public void method1() {
System.out.println("Service2 method1");
}
@Override public void method2() {
System.out.println("Service2 method2");
}
}
class Service2Factory implements ServiceFactory {
@Override public Service getService() {
return new Service2();
}
}
public class Factories {
public static void
serviceConsumer(ServiceFactory fact) {
Service s = fact.getService();
s.method1();
s.method2();
}
public static void main(String[] args) {
serviceConsumer(new Service1Factory());
// 服务完全可以互换
serviceConsumer(new Service2Factory());
}
}
/* Output:
Service1 method1
Service1 method2
Service2 method1
Service2 method2
*/
- 代码中可以看出通过工厂这一中间接口,我们不必在代码中创建Service1和Service2的对象,而是通过工厂创建,这样就可以在不修改代码的情况下,将Service1替换为Service2
- 这种中间层相当于创建框架,当Service里代码很多时,我们可以很方便地进行复用
10.11 新特性:接口的private方法
- Java9之后,接口可以包含private方法,这样就可以在接口中提供方法的实现,而不是在实现类中提供方法的实现
- 此后,default方法和static方法都可以使用private方法,这样就可以避免代码重复
- default方法:接口中具有默认实现的方法.默认方法允许在接口中添加新的方法,而不会破坏已有的实现类。实现类可以选择保留默认方法的实现,也可以重写默认方法来提供自己的实现。
- static方法:静态方法与接口相关联,而不是与实现类的实例相关联。它们可以通过接口名直接调用,无需实例化接口。
- private方法:私有方法只能在接口内部被调用,用于封装和重用代码块。私有方法可以被默认方法或静态方法调用,以提供共享的实现逻辑。
10.12 新特性:密封类和密封接口
- 从JDK17开始引入密封(sealed)类和密封接口,可以限制类或接口的继承关系,只允许特定的类或接口继承或实现该类或接口
sealed class Base permits D1, D2 {}
final class D1 extends Base {}
final class D2 extends Base {}
// 非法:
// final class D3 extends Base {}
sealed interface Ifc permits Imp1, Imp2 {}
final class Imp1 implements Ifc {}
final class Imp2 implements Ifc {}
sealed abstract class AC permits X {}
final class X extends AC {}
- permits关键字允许我们在单独的文件夹中定义子类,如果所有子类在同一文件夹中可不带permits关键字
- 一个sealed类需要至少有一个子类
- sealed的子类只能通过以下修饰符定义
- final:不允许有进一步的子类
- sealed:允许有一组密封子类
- non-sealed:允许有任意子类
//sealed类的层次结构
sealed class Bottom permits Level1 {}
sealed class Level1 extends Bottom permits Level2 {}
sealed class Level2 extends Level1 permits Level3 {}
final class Level3 extends Level2 {}
//sealed类的子类可以接触密封
sealed class Super permits Sub1, Sub2 {}
final class Sub1 extends Super {}
non-sealed class Sub2 extends Super {}
class Any1 extends Sub2 {}
class Any2 extends Sub2 {}
11 内部类
11.1 创建内部类
- 把类定义放在另一个类中,这就是内部类,内部类可以访问外部类的所有成员,而不需要任何特殊条件,内部类就像是一个独立的实体,与外部类有着密切的联系,但是又可以独立于外部类的实例存在
- 普遍的使用情况:外部类有一个方法返回指向内部类的引用,或者外部类的方法接受内部类的引用作为参数,这样就可以在外部类的方法中使用内部类的方法和字段
public class Parcel2 {
class Contents {
private int i = 11;
public int value() { return i; }
}
class Destination {
private String label;
Destination(String whereTo) {
label = whereTo;
}
String readLabel() { return label; }
}
public Destination to(String s) {
return new Destination(s);
}
public Contents contents() {
return new Contents();
}
public void ship(String dest) {
Contents c = contents();
Destination d = to(dest);
System.out.println(d.readLabel());
}
public static void main(String[] args) {
Parcel2 p = new Parcel2();
p.ship("Tasmania");
Parcel2 q = new Parcel2();
// 返回内部类的引用
Parcel2.Contents c = q.contents();
Parcel2.Destination d = q.to("Borneo");
}
}
11.2 到外部类的链接
- 当创建一个内部类时,这个内部类的对象会隐含一个链接,指向用于创建该对象的外围对象.通过该链接,无需任何条件,内部类对象可以访问外围对象的成员.内部类用用对外围对象所有元素的访问权
- 当内部类非static时,内部类对象和外部类对象关联创建
11.3 使用.this和.new
- 当内部类字段和外部类同名时,可以使用this字段.例如,如果内部类为InnerClass,外部类为OuterClass,并且它们都有一个名为field的字段,可以使用OuterClass.this.field来引用外部类的字段。
- 创建内部类对象时,使用.new关键字;同时必须使用外部类的实例来创建内部类的实例,因为内部类对象会暗暗地连接到创建它的外部类对象上,但是如果创建的是静态内部类,则不需要外部类的实例
public class OuterClass {
private int field = 10;
public class InnerClass {
private int field = 20;
public void printFields() {
System.out.println("Inner field: " + this.field); // 内部类的字段
System.out.println("Outer field: " + OuterClass.this.field); // 外部类的字段
}
}
public static void main(String[] args) {
OuterClass outer = new OuterClass();
OuterClass.InnerClass inner = outer.new InnerClass();
inner.printFields();
}
}
11.4 内部类和向上转型
- 用private内部类进行接口实现,可以完全隐藏实现的细节,并且完全不用关心接口的实现是否需要修改,因为内部类完全被封装在了外部类中,所以可以很方便地修改内部类的实现,而不会影响到外部类的使用
- private内部类也不会被上下转型到,因为只有外部类才能够访问内部类
11.5 在方法和作用域中的内部类
-
内部类可以在任意的作用域内定义类,理由如下
-
- 实现某种接口,以便返回或创建一个引用
-
- 作为辅助类,不想公开
-
-
内部类仅在作用域内有效,这种类叫做局部内部类
public class Parcel6 {
private void internalTracking(boolean b) {
if(b) {
class TrackingSlip {
private String id;
TrackingSlip(String s) {
id = s;
}
String getSlip() { return id; }
}
TrackingSlip ts = new TrackingSlip("slip");
String s = ts.getSlip();
}
// 超出作用域范围,不可使用TrackingSlipl类
//- TrackingSlip ts = new TrackingSlip("x");
}
public void track() { internalTracking(true); }
public static void main(String[] args) {
Parcel6 p = new Parcel6();
p.track();
}
}
11.6 匿名内部类
- 匿名内部类:没有名字的内部类,可以在定义一个类的同时实例化该类,这样可以省去编写一个完整的类的步骤,但是匿名内部类不能有构造器,因为它连名字都没有,只能使用一次,用完就不能再用了
public class Parcel7 {
public Contents contents() {
return new Contents() { // 插入内部类定义
private int i = 11;
@Override public int value() { return i; }
}; // 分号不能省略
}
public static void main(String[] args) {
Parcel7 p = new Parcel7();
Contents c = p.contents();
}
}
//如果不使用匿名内部类,就要创建一个完整的类,如下
public class Parcel7b {
class MyContents implements Contents {
private int i = 11;
@Override public int value() { return i; }
}
public Contents contents() {
return new MyContents();
}
public static void main(String[] args) {
Parcel7b p = new Parcel7b();
Contents c = p.contents();
}
}
//有参构造时写法如下
public class Parcel8 {
public Wrapping wrapping(int x) {
// Base constructor call:
return new Wrapping(x) { // [1]将适当的参数传给基类构造器。
@Override public int value() {
return super.value() * 47;
}
}; // [2]标记表达式结束,语法完备性
}
public static void main(String[] args) {
Parcel8 p = new Parcel8();
Wrapping w = p.wrapping(10);
}
}
- 匿名类使用匿名类之外定义的对象时,需保证对象引用是用final修饰的
- 匿名类没有构造器,可以借助实例初始化来达到类似构造器的作用,但只能初始化一次
public class Parcel10 {
public Destination
destination(final String dest, final float price) {//匿名类中的外部引用必须是final的
return new Destination() {
private int cost;
// 匿名类的实例初始化,达到构造器的小狗
{
cost = Math.round(price);
if(cost > 100)
System.out.println("Over budget!");
}
private String label = dest;
@Override
public String readLabel() { return label; }
};
}
public static void main(String[] args) {
Parcel10 p = new Parcel10();
Destination d = p.destination("Tasmania", 101.395F);
}
}
- 与普通类相比,匿名类有着局限性,要么是扩展一个类,要么实现一个接口,但是不能两者兼备
- 同时匿名类不能是抽象类,因为匿名类没有名字,所以无法提供给其他代码
- 实现接口时,也只能实现一个
11.7 嵌套类
-
如果不需要内部类和外部类之间的链接,可以将内部类设置为static,此时称之为嵌套类,这意味着
-
- 不需要一个外部类的对象来创建嵌套类对象
-
- 无法从嵌套类的对象中访问非静态的外部类对象
-
- 二者之间更像是一种命名空间的关系,内部类在外部类这个命名空间下
-
-
普通内部类和嵌套类也有不同:普通内部类中不能有static字段和方法,嵌套类可以
- 因为普通内部类是依附于外部类的实例的,但static应该依附于类,这与static定义矛盾,编译器会禁止这一行为
- 而嵌套类不依赖于外部类的实例,因此可以使用static
11.7.1 接口中的类
- 接口中的任何类都是public和static的,因此接口嵌套类自动是public和static的,可以在接口内部创建嵌套类
- 当要创建接口的所有实现都要公用的代码时,可以使用接口内部的嵌套类,这样就可以隐藏实现细节,并将代码置于接口的内部.
- 例子:可以用一个嵌套类存放测试代码,这样就可以很方便地测试接口的各种实现
11.7.2 从多层嵌套的内部类中访问外部成员
- 一个内部类可以被嵌套人亦曾,可以访问任意层次的外部类的所有成员,但是外部类不能访问内部类的成员
class MNA {
private void f() {}
class A {
private void g() {}
public class B {
void h() {
g();
f();
}
}
}
}
public class MultiNestingAccess {
public static void main(String[] args) {
MNA mna = new MNA();
MNA.A mnaa = mna.new A();
MNA.A.B mnaab = mnaa.new B();
mnaab.h();
}
}
11.8 为什么需要内部类
-
内部类最吸引人的原因:每个内部类都能独立地继承自一个(接口的)实现,所以无论外部类是否已经继承了某个(接口的)实现,对于内部类都没有影响
- 内部类完善了多重继承问题的解决方法,每个内部类都能独立继承具体类或抽象类或接口
-
考虑情况
-
- 在一个类需要实现两个接口,那么可以用两种方法,二者无太大区别,可以从问题本质进行选择
-
- 创建一个类实现两个接口
-
- 创建一个类实现一个接口,同时创建一个内部类,让内部类实现另一个接口
-
- 如果一个类要继承两个抽象类或具体类,那么只能使用内部类
-
11.8.1 闭包和回调
-
闭包(closure):一个可调用的对象,它记录了一些信息,这些信息来自于创建它的作用域,可以在任何时刻使用这些信息来调用该对象
- 从该定义看出,内部类是面向外部类对象的闭包,因为它不仅包含外部类对象(创建内部类的作用域),还自动拥有一个指向此外部类对象的引用,并且可以访问其所有成员
-
回调:回调是一种常见的程序设计模式,可以在不改变代码的情况下,让某个特定的方法在特定的时刻被调用
- 例子:事件驱动的GUI程序设计,当用户单击按钮时,按钮对象就会调用程序员预先定义好的方法,这种方法就叫做回调方法
- 如果回调通过指针实现,只能寄希望于程序员操作正确,而Java更为谨慎,语言中没有指针,而内部类提供了同样的解决方案,但更加安全,因为内部类可以完全访问外部类的成员
interface Incrementable {
void increment();
}
// 接口的简单实现
class Callee1 implements Incrementable {
private int i = 0;
@Override public void increment() {
i++;
System.out.println(i);
}
}
class MyIncrement {
public void increment() {
System.out.println("Other operation");
}
static void f(MyIncrement mi) { mi.increment(); }
}
// 当callee2继承MyIncrement时,increment()方法重载了父类的方法
//此时如果实现Incrementable接口,则Incrementable接口的increment()方法调用与父类矛盾,,因此需要使用内部类
class Callee2 extends MyIncrement {
private int i = 0;
@Override public void increment() {
super.increment();
i++;
System.out.println(i);
}
//内部类Closure实现了Incrementable接口,并且调用了外部类的increment()方法,提供了一个指向Callee2的引用,但该引用只能访问increment方法,相当于回调,但是更加安全
private class Closure implements Incrementable {
@Override public void increment() {
Callee2.this.increment();
}
}
Incrementable getCallbackReference() {
return new Closure();
}
}
class Caller {//Caller的构造器接收一个Incrementable的引用,并且在以后的某个时刻,可以使用此引用回调Incrementable的increment()方法
private Incrementable callbackReference;
Caller(Incrementable cbh) {
callbackReference = cbh;
}
void go() { callbackReference.increment(); }
}
public class Callbacks {
public static void main(String[] args) {
Callee1 c1 = new Callee1();
Callee2 c2 = new Callee2();
MyIncrement.f(c2);
Caller caller1 = new Caller(c1);
Caller caller2 =
new Caller(c2.getCallbackReference());
caller1.go();
caller1.go();
caller2.go();
caller2.go();
}
}
- 回调的价值在于灵活性:可以在运行时动态地决定调用哪些方法
- 简单来说就是把一个对象传递给另一个对象,以便后者在合适的时候调用前者的方法
- 回调主要是通过回调函数,回调函数是一个作为参数传递给其他函数的函数,它能够被异步调用以处理某些事件或完成某些任务。
11.8.2 内部类和控制框架
-
应用框架:是一种被设计用来解决某一类特定问题的类和接口的集合,它们的功能被加以通用化,可以应用于多种不同的问题
-
应用框架提供了通用的解决方案,我们在重写方法代码后可以通过定制解决特定的问题,这就是模板方法设计模式
-
控制框架:是一种特殊类型的应用框架,主要是为了满足对事件做出响应的需求.
- 主要对事件做出响应的系统也叫做事件驱动系统,事件驱动系统通常包含一个或多个事件监听器,用来监听某些特定的事件,并且定义了在事件发生时所采取的动作
- 内部类可以简化控制框架的创建和使用
-
考虑一个控制框架,其工作是当事件就绪时执行相应事件,下面给出一个简单的控制框架
- 事件类Event来记录事件的状态,action函数为事件发生时所采取的动作
- Controller类是一个控制框架,addEvent()方法用来添加事件,run()方法用来运行准备好的事件
import java.time.*; // Java 8 time classes
public abstract class Event {
private Instant eventTime;
protected final Duration delayTime;
public Event(long millisecondDelay) {
delayTime = Duration.ofMillis(millisecondDelay);
start();
}
public void start() { // Allows restarting
eventTime = Instant.now().plus(delayTime);
}
public boolean ready() {
return Instant.now().isAfter(eventTime);
}
public abstract void action();
}
import java.util.*;
public class Controller {
private List<Event> eventList = new ArrayList<>();
public void addEvent(Event c) { eventList.add(c); }
public void run() {
while(eventList.size() > 0)
for(Event e : new ArrayList<>(eventList)/*这里创建了列表的副本,防止删除元素影响遍历*/)
if(e.ready()) {
System.out.println(e);
e.action();
eventList.remove(e);
}
}
}
- 对于每一个Event,我们都需要创建一个新的子类,并且覆盖action()方法,这样就可以定制自己的Event,接下来我们就可以使用内部类
-
- 控制框架的整个实现是在一个单独的类中,通过内部类我们可以封装不同的事件,用内部类表达不同的action()
-
- 内部类可以访问外部类的成员,因此可以很方便地修改事件列表,避免代码实现复杂
-
- 下面给出一个具体的例子,例子中
- Bell和Restart比较特殊,用到了外部类的EventList,因此需要使用外部类的引用,这里使用了this关键字
public class GreenhouseControls extends Controller {
private boolean light = false;
public class LightOn extends Event {
public LightOn(long delayTime) {
super(delayTime);
}
@Override public void action() {
light = true;
}
@Override public String toString() {
return "Light is on";
}
}
public class LightOff extends Event {
public LightOff(long delayTime) {
super(delayTime);
}
@Override public void action() {
light = false;
}
@Override public String toString() {
return "Light is off";
}
}
private boolean water = false;
public class WaterOn extends Event {
public WaterOn(long delayTime) {
super(delayTime);
}
@Override public void action() {
water = true;
}
@Override public String toString() {
return "Greenhouse water is on";
}
}
public class WaterOff extends Event {
public WaterOff(long delayTime) {
super(delayTime);
}
@Override public void action() {
water = false;
}
@Override public String toString() {
return "Greenhouse water is off";
}
}
private String thermostat = "Day";
public class ThermostatNight extends Event {
public ThermostatNight(long delayTime) {
super(delayTime);
}
@Override public void action() {
thermostat = "Night";
}
@Override public String toString() {
return "Thermostat on night setting";
}
}
public class ThermostatDay extends Event {
public ThermostatDay(long delayTime) {
super(delayTime);
}
@Override public void action() {
thermostat = "Day";
}
@Override public String toString() {
return "Thermostat on day setting";
}
}
public class Bell extends Event {
public Bell(long delayTime) {
super(delayTime);
}
@Override public void action() {
addEvent(new Bell(delayTime.toMillis()));
}
@Override public String toString() {
return "Bing!";
}
}
public class Restart extends Event {
private Event[] eventList;
public
Restart(long delayTime, Event[] eventList) {
super(delayTime);
this.eventList = eventList;
for(Event e : eventList)
addEvent(e);
}
@Override public void action() {
for(Event e : eventList) {
e.start(); // Rerun each event
addEvent(e);
}
start(); // Rerun this Event
addEvent(this);
}
@Override public String toString() {
return "Restarting system";
}
}
public static class Terminate extends Event {
public Terminate(long delayTime) {
super(delayTime);
}
@Override
public void action() { System.exit(0); }
@Override public String toString() {
return "Terminating";
}
}
}
// 运行控制框架
public class GreenhouseController {
public static void main(String[] args) {
GreenhouseControls gc = new GreenhouseControls();
// 加入控制框架中不同的Event对象,这是命令设计模式的一个例子--eventList中的每个对象都是封装为对象的请求
gc.addEvent(gc.new Bell(900));
Event[] eventList = {
gc.new ThermostatNight(0),
gc.new LightOn(200),
gc.new LightOff(400),
gc.new WaterOn(600),
gc.new WaterOff(800),
gc.new ThermostatDay(1400)
};
gc.addEvent(gc.new Restart(2000, eventList));
gc.addEvent(
new GreenhouseControls.Terminate(5000));
gc.run();
}
}
11.9 继承内部类
- 因为内部类的构造器必须附加一个指向其包围类对象的引用,所以在继承内部类时,事情会变得有点复杂,必须有特殊的语法指明这种关联
- 下面代码中InheritInner继承了内部类,创建构造器时,不能使用默认构造器,需要传递一个指向外部类对象的引用,并且必须在构造器内使用语法
OuterClassName.super()来调用基类构造器
- 下面代码中InheritInner继承了内部类,创建构造器时,不能使用默认构造器,需要传递一个指向外部类对象的引用,并且必须在构造器内使用语法
class WithInner {
class Inner {}
}
public class InheritInner extends WithInner.Inner {
//- InheritInner() {} // 默认构造器会编译失败
InheritInner(WithInner wi) {
wi.super();
}
public static void main(String[] args) {
WithInner wi = new WithInner();
InheritInner ii = new InheritInner(wi);
}
}
11.10 内部类可以被重写吗
- 当继承外部类时,内部类没有特殊之处,因为这两个内部类是两个独立的实体,分别在自己的命名空间中
- 然而,显式地继承某个内部类是可行的
class Egg2 {
protected class Yolk {
public Yolk() {
System.out.println("Egg2.Yolk()");
}
public void f() {
System.out.println("Egg2.Yolk.f()");
}
}
private Yolk y = new Yolk();
Egg2() { System.out.println("New Egg2()"); }
public void insertYolk(Yolk yy) { y = yy; }
public void g() { y.f(); }
}
public class BigEgg2 extends Egg2 {
public class Yolk extends Egg2.Yolk {
public Yolk() {
System.out.println("BigEgg2.Yolk()");
}
@Override public void f() {
System.out.println("BigEgg2.Yolk.f()");
}
}
public BigEgg2() { insertYolk(new Yolk()); }
public static void main(String[] args) {
Egg2 e2 = new BigEgg2();
e2.g();
}
}
/* Output:
Egg2.Yolk()
New Egg2()
Egg2.Yolk()
BigEgg2.Yolk()
BigEgg2.Yolk.f()
*/
11.11 局部内部类
- 内部类也可以在代码块内创建,通常是在方法体中;
- 局部内部类不能使用访问权限修饰符,因为其不是外围类的组成部分,但是它可以访问当前代码块中的常量及外围类的所有成员
- 局部内部类可以和匿名内部类相互替代
- 但局部内部类可以创建多个该类对象,匿名内部类只能返回一个实例
- 局部内部类允许我们i当以具名的构造器和重载半杯,匿名类只能实例初始化
11.12 内部类标识符
- 内部类标识符:在生成的.class文件中,内部类会被编译器重命名,以外部类名$内部类名的形式命名
- 如果内部类是匿名的,编译器会以数字作为内部类标识符。
- 如果内部类嵌套在其他内部类之内,它们的名字会被附加到其外围类标识符和 $ 之后
12 集合
- java.until库有一组完整的集合类,基本的类型是List,Set,Queue,Map.这些类型也叫容器类
- 集合类中不能使用基本类型,要包装类型,但有自动装箱机制,我们不用担心
12.1 泛型和类型安全的集合
-
Java5之前的集合类,编译器允许向集合中插入不正确元素,但会引来很多问题,因此Java5引入了泛型,泛型的基本思想是参数化类型,也就是说所操作的数据类型被指定为一个参数
-
泛型的好处
-
- 类型安全,编译器会检查类型,不会出现向集合中插入错误类型的元素
-
- 消除了强制类型转换,不需要强制类型转换
-
- 代码更加简洁
-
-
定义泛型类实例
//Java7 前前后都需要<Apple>,Java7后可以省略后面的<Apple>
ArrayList<Apple> apples = new ArrayList<Apple>();
ArrayList<Apple> apples = new ArrayList<>();
//在JDK10/11 加入了var关键字,可以自动推断类型,代码更加简洁,但后面<>内必须标明类型,否则默认Object类
var apples = new ArrayList<Apple>();
12.2 基本概念
-
Java集合类库用来"持有对象",从设计上有两个不同的概念,表现为库的两个基本接口
-
- Collection:一个由单独元素组成的序列,这些元素都服从一条或多条规则.
- List必须按照元素插入顺序保存他们;
- Set中不能有重复元素;
- Queue按照排队规则来确定对象产生的顺序
-
- Map:一组键值对象,使用键来查找值
- ArrayList:使用一个数值查找某个元素,广义Map
- Map:使用另一个对象来查找某个对象,也称关联数组或字典
-
-
我们编写的代码总是在和这些接口打交道
//List为接口,ArrayList为实现类,这里相当于向上转型
List<Apple> apples = new ArrayList<>();
//我们可以替换实现类
List<Apple> apples = new LinkedList<>();
//但向上转型并不是总是可以,因为显现类会有自己的方法,而接口中没有
LinkedList<Apple> apples = new LinkedList<>();
-
序列是持有一组对象的一种方式,Collection接口是序列概念的一般化
-
Java集合类库有着完整的体系结构,根接口即为Collection和Map
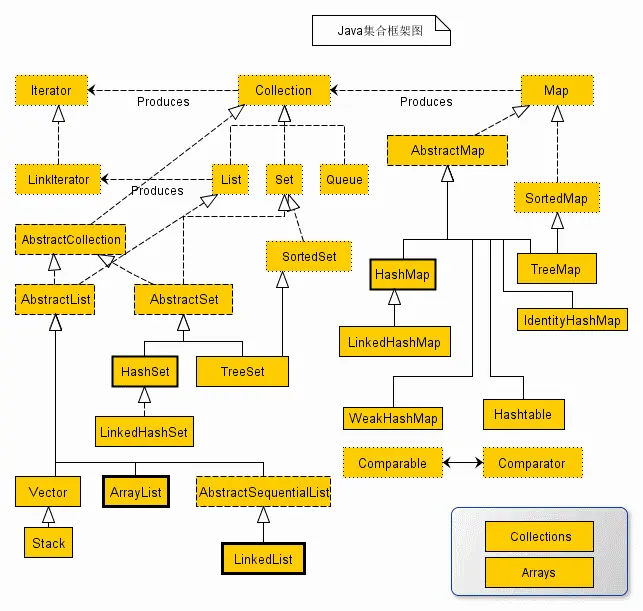
12.3 添加一组元素
- java.util 中的 Arrays 和 Collections 类都包含了一些工具方法,用于向一个 Collection中添加一组元素
- Arrays.asList() 方法:接受一个数组或是用逗号分隔的元素列表,并将其转换为一个 List 对象;底层为数组,无法修改大小
- Collections.addAll() 方法:接受一个 Collection 对象,以及一个数组或是一个用逗号分隔的列表,然后将元素添加到 Collection 中
Collection<Integer> collection = new ArrayList<>(Arrays.asList(1, 2, 3, 4, 5));
Integer[] moreInts = { 6, 7, 8, 9, 10 };
collection.addAll(Arrays.asList(moreInts));
// 运行快很多,但是我们无法以这种方式构建 Collection:
Collections.addAll(collection, 11, 12, 13, 14, 15);
Collections.addAll(collection, moreInts);
// 生成一个底层为数组的列表:
List<Integer> list = Arrays.asList(16,17,18,19,20);
list.set(1, 99); // OK——修改元素
// list.add(21); // 运行时错误;底层的数组不能调整大小
12.4 集合打印
public class PrintingCollections {
static Collection
fill(Collection<String> collection) {
collection.add("rat");
collection.add("cat");
collection.add("dog");
collection.add("dog");
return collection;
}
static Map fill(Map<String, String> map) {
map.put("rat", "Fuzzy");
map.put("cat", "Rags");
map.put("dog", "Bosco");
map.put("dog", "Spot");
return map;
}
public static void main(String[] args) {
System.out.println(fill(new ArrayList<>()));
System.out.println(fill(new LinkedList<>()));
System.out.println(fill(new HashSet<>()));
System.out.println(fill(new TreeSet<>()));
System.out.println(fill(new LinkedHashSet<>()));
System.out.println(fill(new HashMap<>()));
System.out.println(fill(new TreeMap<>()));
System.out.println(fill(new LinkedHashMap<>()));
}
}
/* Output:
[rat, cat, dog, dog]
[rat, cat, dog, dog]
[rat, cat, dog]
[cat, dog, rat]
[rat, cat, dog]
{rat=Fuzzy, cat=Rags, dog=Spot}
{cat=Rags, dog=Spot, rat=Fuzzy}
{rat=Fuzzy, cat=Rags, dog=Spot}
*/
- 集合类可以很漂亮的进行打印,通过toString方法,Collection的内容用方括号包起来,Map的内容用花括号包起来,键值对用等号连接,并且按照键的升序排列
- 上述代码展示了Java集合类库的两种主要类型,区别是集合中每个"槽"(slot)内持有的条目数
- Collection:每个槽只能持有一个元素
- List:按照插入顺序保存元素
- ArrayList和LinkedList
- Set:不能有重复元素
- HashSet
- TreeSet:以升序保存对象
- LinkedHashSet:按照添加顺序来保存对象
- Queue:按照排队规则来确定对象产生的顺序
- List:按照插入顺序保存元素
- Map:每个槽持有两个对象,一个是键,一个是值,键用来查找值
- HashMap:保存顺序不同于插入顺序
- TreeMap:按照键的升序来排序
- LinkedHashMap:按照插入顺序来保存键,同时保留了 HashMap 的查找速度
- Collection:每个槽只能持有一个元素
12.5 List
-
List接口在Collection基础上增加方法,支持在List中间插入和删除元素,有两种基本类型的List
- 基本的ArrayList,擅长随机访问元素,但在List中间插入和删除元素比较慢
- LinkedList,提供了理想的顺序访问性能,在List中间插入和删除元素比较快,但随机访问元素比较慢
-
List 方法
- contains(Object):判断是否包含某个对象
- remove(Object):删除某个对象
- indexOf(Object):返回某个对象的索引
- equals(Object):判断是否相等,两个对象相等的条件是:1.类型相同 2.长度相同 3.每个位置的元素都相同,使用equals()方法判断,而不是==,因为==判断的是对象的引用
- subList(int fromIndex, int toIndex):返回一个子列表,包含fromIndex到toIndex之间的元素,不包含toIndex,即左闭右开
- containsAll(Collection):判断是否包含某个集合中的所有元素
- addAll(Collection):添加某个集合中的所有元素
- removeAll(Collection):删除某个集合中的所有元素
- retainAll(Collection):删除不在某个集合中的所有元素,即取交集
- clear():删除所有元素
- isEmpty():判断是否为空
- toArray():返回一个包含所有元素的数组
- set(int index, E element):将index位置的元素替换为element
-
Collectons静态方法
- Collections.shuffle(List):随机打乱List中的元素
- Collections.sort(List):按照自然顺序排序
12.6 Iterator
- 迭代器(也是一种设计模式)的概念实现了一种抽象的接口,用来遍历容器中的元素,迭代器提供了一种通用的方式来遍历容器中的所有元素,并且不需要关心容器的具体类型
- Java迭代器只能向一个方向移动,有以下几点
-
- 使用iterator()方法让Collection返回一个Iterator对象,该迭代器准备返回序列中的第一个元素
-
- 使用next()方法获得序列中的下一个元素
-
- 使用hasNext()方法检查序列中是否还有元素
-
- 使用remove()方法将迭代器新返回的元素删除
-
public class SimpleIteration {
public static void main(String[] args) {
List<Pet> pets = new PetCreator().list(12);
Iterator<Pet> it = pets.iterator();
while(it.hasNext()) {
Pet p = it.next();
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
// 迭代器更简单的写法
for(Pet p : pets)
System.out.print(p.id() + ":" + p + " ");
System.out.println();
// 迭代器删除元素
it = pets.iterator();
for(int i = 0; i < 6; i++) {
it.next();
it.remove();
}
System.out.println(pets);
}
}
- 迭代器统一了对集合的访问;使用Iterable接口,我们可以编写能够作用于任何Collection对象的方法
- 例子:下面的display()方法可以接受任何实现了Iterable接口的对象
public static void display(Iterable<Pet> ip) {
Iterator<Pet> it = ip.iterator();
while(it.hasNext()) {
Pet p = it.next();
System.out.print(p.id() + ":" + p + " ");
}
System.out.println();
}
public static void main(String[] args) {
List<Pet> pets = new PetCreator().list(8);
LinkedList<Pet> petsLL = new LinkedList<>(pets);
HashSet<Pet> petsHS = new HashSet<>(pets);
TreeSet<Pet> petsTS = new TreeSet<>(pets);
display(pets);
display(petsLL);
display(petsHS);
display(petsTS);
}
- ListIterator
- ListIterator是Iterator的子类型,只能用于各种List类的访问,可以双向移动
- nextIndex(),previousIndex() 可以产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引
- set()方法替换它访问过的最后一个元素
- add()方法在它访问过的位置插入一个元素
- listIterator(n):生成一个指向列表中索引为 n 的元素处的 ListIterator
public class ListIteration {
public static void main(String[] args) {
List<Pet> pets = new PetCreator().list(8);
ListIterator<Pet> it = pets.listIterator();
while(it.hasNext())
System.out.print(it.next() +
", " + it.nextIndex() +
", " + it.previousIndex() + "; ");
/*
1. 这里输出中函数调用顺序是从左到右
2. 这里需要对next实现理解,首先it.next()返回的是当前元素,然后指针向后移动一位,指向下一个元素,所以it.nextIndex()返回的其实是当前指针指向元素的索引
public E next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
E value = currentNode.getValue();
currentNode = currentNode.getNext();
return value;
}
*/
System.out.println();
// 反向:
while(it.hasPrevious())
System.out.print(it.previous().id() + " ");
System.out.println();
System.out.println(pets);
it = pets.listIterator(3);
while(it.hasNext()) {
it.next();
it.set(new PetCreator().get());
}
System.out.println(pets);
}
}
/* Output:
Rat, 1, 0; Manx, 2, 1; Cymric, 3, 2; Mutt, 4, 3; Pug,
5, 4; Cymric, 6, 5; Pug, 7, 6; Manx, 8, 7;
7 6 5 4 3 2 1 0
[Rat, Manx, Cymric, Mutt, Pug, Cymric, Pug, Manx]
[Rat, Manx, Cymric, Rat, Rat, Rat, Rat, Rat]
*/
12.7 LinkedList
- LinkedList是一个双向链表,可以快速地在List中间插入和删除元素,但随机访问元素比较慢,其实现了基本的List接口,也添加了一些可以用于栈,队列或双端队列的方法
-
- getFirst(),element():返回列表的第一个元素,但不删除;如果列表为空,抛出NoSuchElementException;peek():返回列表的第一个元素,但不删除;如果列表为空,返回null
-
- removeFirst(),remove():返回列表的第一个元素,并删除;如果列表为空,抛出NoSuchElementException;poll():返回列表的第一个元素,并删除;如果列表为空,返回null
-
- addFirst():将元素插入到列表的前面;
-
- addLast(),offer(),add():将元素添加到列表的末尾
-
- removeLast():返回列表的最后一个元素,并删除;
- 上述方法都有些微小差别,需要在使用时注意
-
12.8 Stack
- Java1.0 提供了Stack类,但实现很糟糕,不过因为要向后兼容,所以一直保留了下来,但是不建议使用
- Java6 加入了ArrayDeque,提供了直接实现栈功能的方法
- 总之,Java中java.util.Stack的栈方法不建议使用,而是使用java.util.ArrayDeque或其他方法模拟栈
12.9 Set
- Set是一种不保存重复元素的Collection,Set接口没有提供额外的方法,只是限制了Collection中不能有重复元素
- HashSet使用Hash提升速度,输出的顺序没有规律
- TreeSet使用红黑树实现,按照升序保存对象
- LinkedHashSet按照添加顺序保存对象,也是用哈希表实现的,但是同时维护了一个链表,因此性能略低于HashSet,但是迭代访问Set中的元素时,性能比HashSet好
12.10 Map
- Map是一种关联数组,也称为字典或者是键值对,Map中的每个元素都包含一个键对象和一个值对象,每个键只能出现一次,但是可以多次出现相同的值;因此Map可以方便的扩展到多维
- Boolean containsKey(Object):判断是否包含某个键
- Boolean containsValue(Object):判断是否包含某个值
- V get(Object):返回某个键对应的值
- V put(K key, V value):添加键值对
- V remove(Object):删除某个键值对
- int size():返回键值对的个数
- void clear():删除所有键值对
- boolean isEmpty():判断是否为空
- Set
keySet():返回所有键组成的Set - Collection
values():返回所有值组成的Collection - Set<Map.Entry<K, V>> entrySet():返回所有键值对组成的Set
- Map.Entry<K, V>:是Map中的一个内部接口,表示一个键值对,包含getKey(),getValue(),setValue()方法
- 遍历Map的最佳方法,使用
for (Map.Entry<String, Integer> entry : map.entrySet())-
- 效率高
-
- 简单易读
-
- 支持键值对操作
- 但该方法返回的集合视图不可修改,修改或删除需要使用Map接口提供的其他方法
-
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("Key: " + key + ", Value: " + value);
}
12.11 新特性:记录(record)类型
-
Map使用的障碍:键的对象必须要定义两个函数:hashCode()和equals(),这两个函数必须要一致
-
JDK16 新增 record关键字.record定义的是希望称为数据传输对象(也叫数据载体)的类,使用record时,编译器自动生成
-
- 私有的final字段,用来保存每个组件的状态
-
- 公共的构造器,用来初始化每个组件的状态
-
- 公共的访问器方法,用来访问每个组件的状态
-
- equals()方法,用来比较两个记录是否相等
-
- hashCode()方法,用来生成记录的哈希码
-
- toString()方法,用来生成记录的字符串表示形式
-
-
例子:
import java.util.*;
record Employee(String name, int id) {}
public class BasicRecord {
public static void main(String[] args) {
var bob = new Employee("Bob Dobbs", 11);
var dot = new Employee("Dorothy Gale", 9);
// bob.id = 12; // 错误:
// id 在 Employee 中的访问权限为 private
System.out.println(bob.name()); // 访问器
System.out.println(bob.id()); // 访问器
System.out.println(bob); // toString()
// Employee 可以用做 Map 中的键:
var map = Map.of(bob, "A", dot, "B");
System.out.println(map);
}
}
/* Output:
Bob Dobbs
11
Employee[name=Bob Dobbs, id=11]
{Employee[name=Dorothy Gale, id=9]=B, Employee[name=Bob Dobbs, id=11]=A}
*/
- record只需要名字和参数即可
-
- 参数自动变为 private final 的字段
-
- 不能再record内部定义字段,但可以加入静态的字段,初始值
-
- 可以定义方法,但只能使用参数,不能修改,因为参数是final的
-
- record不能继承或者被继承,其隐含为final的,但可以实现接口
- 例子:编译器会强制我们实现density()方法,但不会因为brightness()方法而报错,因为brightness()方法在record自动生成的访问器中已经实现了
interface Star {
double brightness();
double density();
}
record RedDwarf(double brightness) implements Star {
@Override public double density() { return 100.0; }
}
- record可以被嵌套和局部使用,此时record都是静态的
- record会自动创建一个规范的构造器,但我们可以使用**紧凑构造器(compact)**来添加构造器行为
- 紧凑构造器的参数必须是record的参数,且必须在record的参数之后
- 紧凑构造器常用来验证参数,或者是对参数进行修改,也可以调用外部函数
- 例子:下面的紧凑构造器会将id的值加1
record Employee(String name, int id) {
Employee {
if (id < 1) throw new IllegalArgumentException();
id++;
}
}
- 也可以使用普通构造器语法替换掉自动生成的构造器,构造器必须精确复制这个 record 的签名,但是必须使用this()调用自动生成的构造器,
record Employee(String name, int id) {
Employee(String name) {
this.name = name;
}
}
12.12 Queue
-
Queue是一个典型的先进先出(FIFO)的容器,Queue接口继承了Collection接口,并添加了一些额外的方法
-
- add():将元素插入到队尾,如果插入成功,返回true,否则抛出异常
-
- offer():将元素插入到队尾,如果插入成功,返回true,否则返回false
-
- remove():返回队头元素,如果队列为空,抛出异常
-
- poll():返回队头元素,如果队列为空,返回null
-
- element():返回队头元素,如果队列为空,抛出异常
-
- peek():返回队头元素,如果队列为空,返回null
-
-
LinkedList实现了Queue接口,因此可以直接使用LinkedList来实现队列
public class QueueDemo {
public static void printQ(Queue queue) {
while(queue.peek() != null)
System.out.print(queue.remove() + " ");
System.out.println();
}
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
Random rand = new Random(47);
for(int i = 0; i < 10; i++)
queue.offer(rand.nextInt(i + 10));
printQ(queue);
Queue<Character> qc = new LinkedList<>();
for(char c : "Brontosaurus".toCharArray())
qc.offer(c);
printQ(qc);
}
}
PriorityQueue
- Java5中添加PriorityQueue,为Queue的优先队列的实现,其内部使用堆来实现,可以使用Comparator来控制元素的排序
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue = new PriorityQueue<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7));
priorityQueue = new PriorityQueue<>(size, Collections.reverseOrder());//这里即使用了Comparator,使用了Collections.reverseOrder()来反转排序
priorityQueue = new PriorityQueue<>(comparator);//使用自己定义的比较器
Comparator<Integer> comparator = new Comparator<Integer>() {
@Override public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
};
12.13 Collection和Iterator
-
Collection接口是所有Collection类的根接口,它提供了一组标准的集合操作,包括添加,删除,查找,遍历等;此外,java.util.AbstractCollection类提供了Collection接口的默认实现,以减少实现Collection接口所需的工作量
-
C标准库中的集合类没有公共基类,集合之间共性通过迭代器实现,Java也遵循C的方式,但Java中Collection接口继承了Iterable接口,所以Java中实现Collection也就意味着有了Iterator()方法
public static <T> void display(Iterator<T> it) {
while(it.hasNext()) {
T obj = it.next();
System.out.print(obj.toString() + " ");
}
System.out.println();
}
public static <T> void display(Collection<T> collection) {
for(T obj : collection)
System.out.print(obj.toString() + " ");
System.out.println();
}
- 上面两个版本的display()方法都可以接受任何Collection对象,但是第一个版本使用了Iterator,因此可以用于任何实现了Iterable接口的对象,而第二个版本只能用于Collection对象
- 当有一个不是Collection的外部类时,我们可以让它实现Iterable接口,这样就可以使用适合Iterable接口的语法了
- 生成一个Iterator, 是将序列与处理序列的方法连接起来的耦合性最低的方式,与实现 Collection 相比,这样做对序列类的约束要少得多。
class PetSequence {
protected Pet[] pets = new PetCreator().array(8);
}
public class NonCollectionSequence extends PetSequence {
public Iterator<Pet> iterator() {
return new Iterator<Pet>() {
private int index = 0;
@Override public boolean hasNext() {
return index < pets.length;
}
@Override
public Pet next() { return pets[index++]; }
@Override
public void remove() { // Not implemented
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) {
NonCollectionSequence nc =
new NonCollectionSequence();
InterfaceVsIterator.display(nc.iterator());
}
}
12.14 for-in与迭代器
- for-in使用Iterable接口来遍历Collection,因此所有实现Iterable接口的类都可以使用for-in来遍历. 数组可以通过Arrays.asList()方法转换为List,从而可以使用for-in来遍历数组.
public class IterableClass implements Iterable<String> {
protected String[] words = ("And that is how " +
"we know the Earth to be banana-shaped."
).split(" ");
@Override public Iterator<String> iterator() {
return new Iterator<String>() {
private int index = 0;
@Override public boolean hasNext() {
return index < words.length;
}
@Override
public String next() { return words[index++]; }
@Override
public void remove() { // Not implemented
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) {
for(String s : new IterableClass())
System.out.print(s + " ");
}
}
public class ArrayIsNotIterable {
static <T> void test(Iterable<T> ib) {
for(T t : ib)
System.out.print(t + " ");
}
public static void main(String[] args) {
test(Arrays.asList(1, 2, 3));
String[] strings = { "A", "B", "C" };
// An array works in for-in, but it's not Iterable:
//- test(strings);
// You must explicitly convert it to an Iterable:
test(Arrays.asList(strings));
}
}
适配器方法
- 如何在实现Iterable接口后,让这个类有不止一种方式用在for-in语句中
- 使用**适配器方法(Adapter Method)**的惯用法,即在类中添加一个返回Iterable的方法,这个方法可以用于for-in语句中
- 例子:下面的ReversibleArrayList类,实现了Iterable接口,并且添加了一个适配器方法,可以返回一个Iterable对象,这个对象可以用于for-in语句中;
- 适配器方法其实相当于给原本的方法套一个匿名内部类的皮,这个匿名内部类实现了Iterable接口,并且返回了一个Iterator对象,外部类的适配器方法返回的就是这个匿名内部类对象
public class MultiIterableClass extends IterableClass {
public Iterable<String> reversed() {
return new Iterable<String>() {
public Iterator<String> iterator() {
return new Iterator<String>() {
int current = words.length - 1;
@Override public boolean hasNext() {
return current > -1;
}
@Override public String next() {
return words[current--];
}
@Override
public void remove() { // Not implemented
throw new UnsupportedOperationException();
}
};
}
};
}
public Iterable<String> randomized() {
return new Iterable<String>() {
public Iterator<String> iterator() {
List<String> shuffled =
new ArrayList<>(Arrays.asList(words));
Collections.shuffle(shuffled, new Random(47));
return shuffled.iterator();
}
};
}
public static void main(String[] args) {
MultiIterableClass mic = new MultiIterableClass();
for(String s : mic.reversed())
System.out.print(s + " ");
System.out.println();
for(String s : mic.randomized())
System.out.print(s + " ");
System.out.println();
for(String s : mic)
System.out.print(s + " ");
}
}
12.15 总结
Java提供了很多持有对象的方式
- 数组将数字索引和对象关联起来.数组的效率最高,但是容量固定
- Collection保存单个对象,而Map保存关联的键值对;
- 利用Java泛型可以指定保存在集合中的对象的类型
- Collection和Map都可以自动调整大小
- 集合不能保存基本数据类型,但是可以使用基本数据类型的包装器类
- 类似数组,List也可以将数字索引和对象关联起来,但是List可以自动调整大小
- 如果要执行大量随机访问,使用ArrayList;如果要在列表中间执行大量删除和插入,使用LinkedList
- 队列和栈的行为都是通过LinkedList来实现的
- Map将对象而非整型值和其他对象关联起来
- HashMap提供了最快的查找技术
- TreeMap将键有序保存,不如HashMap快
- LinkedMap按照元素插入的顺序保存键,但通过Hash提供了快速访问能力
- 对于相同元素,Set只保存一个
- HashSet提供了最快的查找技术
- TreeSet将键有序保存
- LinkedSet按照元素插入的顺序保存键
- 不要在新代码中使用Vector,HashTable和Stack等遗留类
-
Java集合类的简化图(没有抽象类或遗留组件),只包含常见接口和类
- 虚线框表示接口,实现框为实现类,最常用集合边框加粗
- 箭头表示继承关系,实现类实现了接口
- 带有"Produces"的箭头标明一个类可以生成箭头所指类的对象
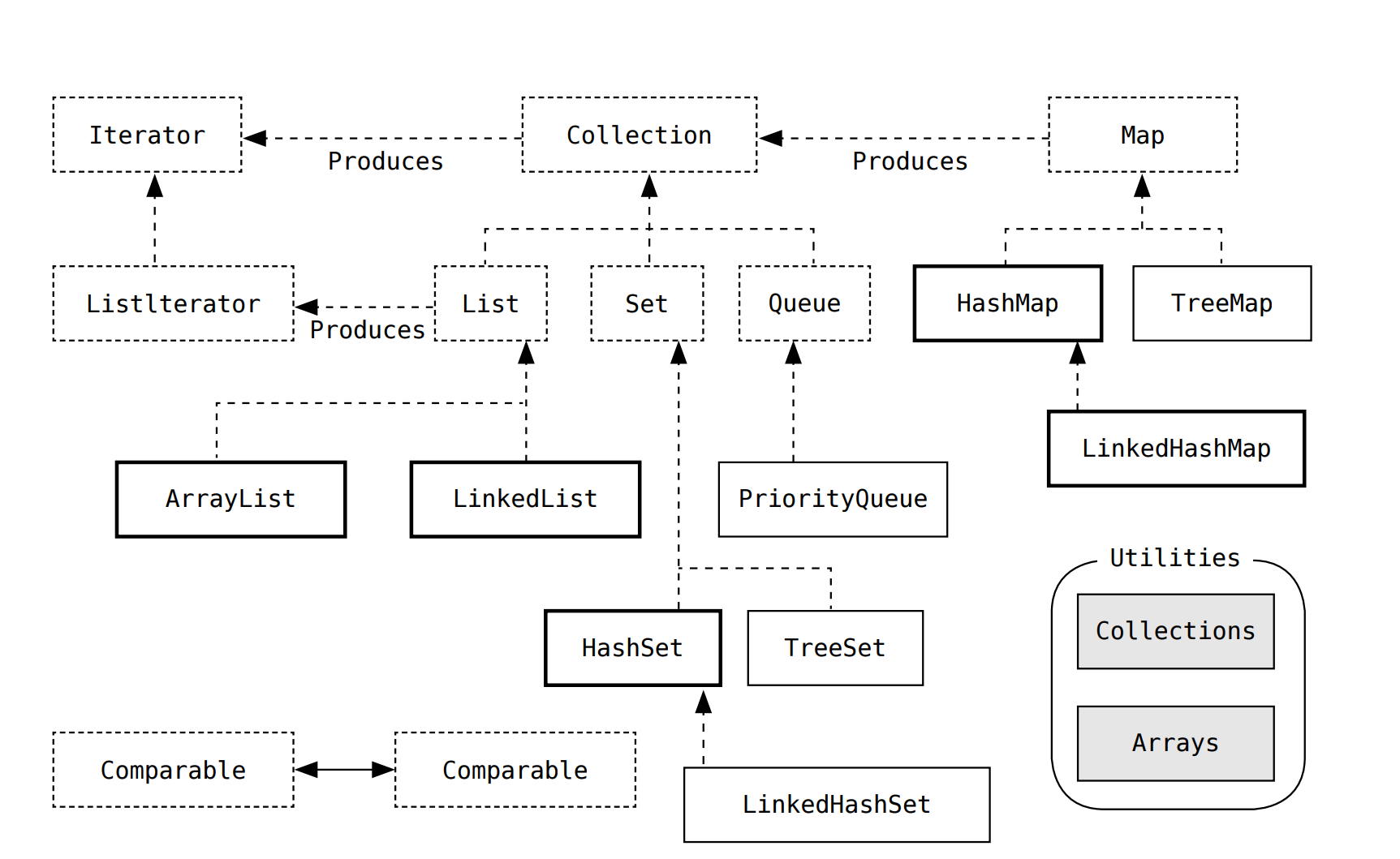
-
从面向对象的层次结构看,这种组织方式有点奇怪。然而随着你对 java.util 中的集合类有了更深入的了解,会有更多的问题,而不只是奇怪的继承结构.设计集合类库总是存在各种困难,我们要满足往往存在冲突的不同诉求。所以要准备好在这里或那里做出一些妥协
13 函数式编程
- 早期,为了让程序适应有限的内存,程序员会在程序执行时修改内存中的代码,来节省代码空间.这就是自修改代码技术
- 然而随着程序越来复杂,代码需要更加一致和易懂,并且硬件越来便宜,自修改代码的方法已经落后.然而代码操纵其它代码的思想依然很吸引人,但需要更安全的实现
- 这就是函数式编程(functional programming,FP)的意义所在,它是一种编程范式,可以将计算机运算视为数学函数的计算,避免了状态和可变数据,强调函数的运算结果而非运算过程,以及函数之间的调用关系来解决问题
- 面向对象编程抽象数据,函数式编程抽象行为
- 纯函数式语言要求所有数据是不可变的,函数接收值,然后产生新值,而不是修改参数的值,因此纯函数式语言中的函数没有副作用,也就是说,函数不会修改外部的状态,也不会依赖外部的状态,函数的输出只依赖于输入,这样的函数称为纯函数(pure function)
13.1 新方式和旧方式
- 旧方式:创建一个对象,让其一个方法包含所需行为,然后将这个对象传递给另一个方法,这个方法可以调用对象的方法来执行所需的行为
- Java8的新方式:方法引用和lambda表达式
13.2 lambda表达式
- lambda表达式是使用尽可能少的语法编写的函数定义
- 在JVM中,所有都是对象,所以lambda也是一个对象,所以使用lambda表达式时,实际上是创建了一个对象,这个对象是一个函数式接口的实例
- lambda表达式基础语法
-
- 参数
-
- 后面跟 -> ,可以称作"产生"(produces)
-
- ->后都是方法体
-
interface Description {
String brief();
}
interface Body {
String detailed(String head);
}
interface Multi {
String twoArg(String head, Double d);
}
public class LambdaExpressions {
static Body bod = h -> h + " No Parens!"; // [1]
static Body bod2 = (h) -> h + " More details"; // [2]
static Description desc = () -> "Short info"; // [3]
static Multi mult = (h, n) -> h + n; // [4]
static Description moreLines = () -> { // [5]
System.out.println("moreLines()");
return "from moreLines()";
};
public static void main(String[] args) {
System.out.println(bod.detailed("Oh!"));
System.out.println(bod2.detailed("Hi!"));
System.out.println(desc.brief());
System.out.println(mult.twoArg("Pi! ", 3.14159));
System.out.println(moreLines.brief());
}
}
/* Output:
Oh! No Parens!
Hi! More details
Short info
Pi! 3.14159
moreLines()
from moreLines()
*/
- 上述代码中,[1] 到 [5]的lambda实现了接口中的方法
- [1] [2] 只有一个参数,可以省略参数的括号,但为了一致性,最好加上
- [3] 没有参数,需要使用括号
- [4] 有多个参数,需要使用括号,且用","隔开,需要注意参数类型的一致性
- [1]到[4]的方法体只有一行,此时方法式中表达式的结果会自动成为lambda表达式的返回值,此处使用return关键字非法,
- [5] 如果lambda表达式需要多行代码,此时必须将代码放在花括号中,此时需要使用return关键字来返回值
递归
- Java中可以编写递归的lambda表达式,但此时该lambda表达式必须给赋值给一个静态变量或一个实例变量,否则会出现编译错误
- 例子:此处主函数里fact是一个静态InCall变量,需要注意的是,这里不能直接使用lambda表达式,而是需要先声明一个变量,然后再使用lambda表达式赋值给这个变量,因为lambda表达式是一个对象,而不是一个方法
interface IntCall {
int call(int arg);
}
public class RecursiveFactorial {
static IntCall fact;
// static IntCall fact = n -> n == 0 ? 1 : n * fact.call(n - 1); 这样会编译错误,对Java编译器太过复杂
public static void main(String[] args) {
fact = n -> n == 0 ? 1 : n * fact.call(n - 1);
for(int i = 0; i <= 10; i++)
System.out.println(fact.call(i));
}
}
13.3 方法引用
- 方法引用是用 类名或对象名后跟 ::,然后方法名
interface Callable { // [1] 是一个包含一个方法的接口
void call(String s);
}
class Describe {
void show(String msg) { // [2] show的**签名**(参数类型和返回类型) 和Callable中call()的签名一致
System.out.println(msg);
}
}
public class MethodReferences {
static void hello(String name) { // [3] hello()的签名和Callable中call()的签名一致
System.out.println("Hello, " + name);
}
static class Description {
String about;
Description(String desc) { about = desc; }
void help(String msg) { // [4] help()的签名和Callable中call()的签名一致,为静态内部类的非静态方法
System.out.println(about + " " + msg);
}
}
static class Helper {
static void assist(String msg) { // [5] assist()的签名和Callable中call()的签名一致,为静态内部类的静态方法
System.out.println(msg);
}
}
public static void main(String[] args) {
Describe d = new Describe();
Callable c = d::show; // [6]将show方法的引用赋给一个Callable对象,此时相当于show方法为Callable接口的call方法的实现
c.call("call()"); // [7]调用call()方法,实际上是调用了show()方法,因为Java将call映射到了show上
c = MethodReferences::hello; // [8] 静态方法可以不创建实例
c.call("Bob");
c = new Description("valuable")::help; // [9] 这是[6]的另一个实现,需要创建实例
c.call("information");
c = Helper::assist; // [10] 静态内部类的静态方法
c.call("Help!");
}
}
/* Output:
call()
Hello, Bob
valuable information
Help!
*/
13.3.1 Runnable接口
- Runnable接口在Java.lang包中,不需要import,它只有一个run()方法,没有参数,也没有返回值,因此可以使用lambda表达式或方法引用来实现
- 例子:Tread对象接收一个Runnable对象作为其构造器,其有一个start方法会调用run()方法,因此可以使用lambda表达式或方法引用来实现
class Go {
static void go() {
System.out.println("Go::go()");
}
}
public class RunnableMethodReference {
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
System.out.println("Anonymous");
}
}).start();
new Thread(
() -> System.out.println("lambda")
).start();
new Thread(Go::go).start();
}
}
13.3.2 未绑定方法引用
- 未绑定方法引用(unbound method reference)指的是尚未关联到某个对象的普通(非
静态)方法。对于未绑定引用,必须先提供对象,然后才能使用
class X {
String f() { return "X::f()"; }
}
interface MakeString {
String make();
}
interface TransformX {
String transform(X x);
}
public class UnboundMethodReference {
public static void main(String[] args) {
// MakeString ms = X::f; // [1]
TransformX sp = X::f;
X x = new X();
System.out.println(sp.transform(x)); // [2]
System.out.println(x.f()); // 效果相同
}
}
-
[1] 处编译器会报错,提示 无效方法引用”(invalid method reference),即使make()的签名和f()相同,这里需要重点理解:
- 这里涉及一个隐藏的参数:this,如果没有可以附着的X对象,就无法调用f(),因此,X::f是一个未绑定的方法引用,其没有绑定到某个对象,因此无法调用
- 所以我们的接口还需要一个额外的参数,如TransformX接口中的transform()方法,其需要一个X对象作为参数,那么我们就可以使用X::f来实现这个接口
- 即在未绑定引用的情况下,函数式方法(接口中的单一方法)的签名和方法引用的签名不再完全匹配,此时我们需要一个对象,让方法在其上调用
-
[2]处因为接受了未绑定引用,然后调用了transform()方法,传入了一个X对象,因此可以正常运行,即Java知道它需要接收第一个参数,即this指针,然后调用f()方法
-
综上所述,未绑定方法的引用,其X::f的第一个参数是其this指针,即需要额外传入一个对象,然后才能调用f()方法,下面为有参数的情况
class This {
void two(int i, double d) {}
void three(int i, double d, String s) {}
void four(int i, double d, String s, char c) {}
}
//下面为函数式方法,第一个参数都是this指针,意味着使用该方法时需要额外传入对象
interface TwoArgs {
void call2(This athis, int i, double d);
}
interface ThreeArgs {
void call3(This athis, int i, double d, String s);
}
interface FourArgs {
void call4(
This athis, int i, double d, String s, char c);
}
public class MultiUnbound {
public static void main(String[] args) {
TwoArgs twoargs = This::two;
ThreeArgs threeargs = This::three;
FourArgs fourargs = This::four;
This athis = new This();
twoargs.call2(athis, 11, 3.14);
threeargs.call3(athis, 11, 3.14, "Three");
fourargs.call4(athis, 11, 3.14, "Four", 'Z');
}
}
13.3.3 构造器方法引用
class Dog {
String name;
int age = -1; // For "unknown"
Dog() { name = "stray"; }
Dog(String nm) { name = nm; }
Dog(String nm, int yrs) { name = nm; age = yrs; }
}
interface MakeNoArgs {
Dog make();
}
interface Make1Arg {
Dog make(String nm);
}
interface Make2Args {
Dog make(String nm, int age);
}
public class CtorReference {
public static void main(String[] args) {
MakeNoArgs mna = Dog::new; // [1]
Make1Arg m1a = Dog::new; // [2]
Make2Args m2a = Dog::new; // [3]
Dog dn = mna.make();
Dog d1 = m1a.make("Comet");
Dog d2 = m2a.make("Ralph", 4);
}
}
- 上述代码中,Dog有三个构造器,分别为无参构造器,一个参数的构造器,两个参数的构造器
- 这三个构造器只有一个名字new,但可以通过接口来判断是那个构造器
13.4 函数式接口
- 方法引用和lambda表达式都要赋值,赋值就需要类型信息
- 如何确定方法的参数类型呢,为此Java8引入包含一组接口的Java.util.function,这些接口时lambda表达式和方法引用的目标类型,每个接口只包含一个抽象方法,叫做函数式方法
- 当编写接口时,这种"函数式方法"可以使用@FunctionalInterface注解来强制编译器只接受函数式接口
- 例子: @FunctionalInterface注解的使用
- @FunctionalInterface注解 是可选的,一旦出现,该接口只能拥有一个函数式方法,否则编译器会报错
- 使用了 @FunctionalInterface 注解的接口也叫作单一抽象方法(Single Abstract Method, SAM)类型
- 我们可以将方法直接赋给函数式接口,这是Java8增加的魔法:如果我们将一个方法引用或lambda表达式赋值给某个函数式接口(而且类型可以匹配),那么Java会调整这个赋值,使其匹配目标接口。而在底层,Java 编译器会创建一个实现了目标接口的类的实例,并将我们的方法引用或 lambda 表达式包裹在其中
- 这种魔法使得语法更好,更简单
@FunctionalInterface
interface Functional {
String goodbye(String arg);
}
interface FunctionalNoAnn {
String goodbye(String arg);
}
/*
@FunctionalInterface
interface NotFunctional {
String goodbye(String arg);
String hello(String arg);
}
产生报错信息:
NotFunctional is not a functional interface
multiple non-overriding abstract methods
found in interface NotFunctional
*/
public class FunctionalAnnotation {
public String goodbye(String arg) {
return "Goodbye, " + arg;
}
public static void main(String[] args) {
FunctionalAnnotation fa =
new FunctionalAnnotation();
Functional f = fa::goodbye;
FunctionalNoAnn fna = fa::goodbye;
// Functional fac = fa; // Incompatible
Functional fl = a -> "Goodbye, " + a;
FunctionalNoAnn fnal = a -> "Goodbye, " + a;
}
}
- java.util.function 旨在创建一套足够完备的目标接口,这样一般情况下我们就不需要定义自己的接口了。然后由于基本类型的缘故,接口很多,但我们可以通过理解其命名规则知道特定接口. 这里不多赘述,用时再查
- 使用java.util.function的函数式接口时,名字并不重要,重要的只有参数类型和返回类型,Java会将我们的函数自动映射到函数式接口中的方法上,需要调用函数式接口里的函数

- 使用java.util.function的函数式接口时,名字并不重要,重要的只有参数类型和返回类型,Java会将我们的函数自动映射到函数式接口中的方法上,需要调用函数式接口里的函数
13.4.1 带有更多参数的函数式接口
@FunctionalInterface
public interface TriFunction<T, U, V, R> {
R apply(T t, U u, V v);
}
public class TriFunctionTest {
static int f(int i, long l, double d) { return 99; }
public static void main(String[] args) {
TriFunction<Integer, Long, Double, Integer> tf =
TriFunctionTest::f;
tf = (i, l, d) -> 12;
}
}
13.4.2 解决缺乏基本类型函数式接口的问题
- 因为基本类型设计自动装箱和拆箱,因此会有性能问题,因此Java8基本类型的函数式接口缺失,但我们可以自己定义
13.5 高阶函数
- 高阶函数只是一个能接受函数作为参数或能把函数当返回值的函数。
interface FuncSS extends Function<String, String> {} // [1] 使用继承为专门的接口起一个别名
public class ProduceFunction {
static FuncSS produce() {//该函数可以返回一个函数
return s -> s.toLowerCase();
}
public static void main(String[] args) {
FuncSS f = produce();
System.out.println(f.apply("YELLING"));
}
}
- 接收使用函数时需要主要正确描述函数的类型,同时在函数中可以生成一个新的函数
- 下面例子中,transform()接受一个方法同时也生成一个方法
- 这里使用了Function 接口中的一个叫作andThen()的默认(default)方法,该方法
是为操作函数而设计。andThen()会在in函数调用之后调用(还有一个compose的方法,可以在in函数之前应用新函数)
- 这里使用了Function 接口中的一个叫作andThen()的默认(default)方法,该方法
class I {
@Override public String toString() { return "I"; }
}
class O {
@Override public String toString() { return "O"; }
}
public class TransformFunction {
static Function<I,O> transform(Function<I,O> in) {
return in.andThen(o -> {
System.out.println(o);
return o;
});
}
public static void main(String[] args) {
Function<I,O> f2 = transform(i -> {
System.out.println(i);
return new O();
});
O o = f2.apply(new I());
}
}
/* Output:
I
O
*/
13.6 闭包
- 当lambda表达式使用了其函数作用域之外的变量时,会发生什么?
- 这就是闭包的概念,如果语言能解决这个问题,称这个语言是支持闭包的,也可以称之为支持语法作用域
- 这里同时也有一个变量捕获的术语,即lambda表达式捕获了其作用域之外的变量
public class Closure1 {
int i;
IntSupplier makeFun(int x) {
return () -> x + i++;
}
}
- Closure1中,因为变量i位于对象中,随意遍历makeFun返回的函数中,i可以指向正确的位置,因此会有多个函数全部共享i的存储空间
public class Closure2 {
IntSupplier makeFun(int x) {
int i = 0;
return () -> x + i;
}
}
public class Closure3 {
IntSupplier makeFun(int x) {
int i = 0;
// x++ 或 i++ 都不可以:
return () -> x++ + i++;
}
}
error:
local variables referenced from a lambda
expression must be final or effectively final
- Closure3中,i为临时变量,函数返回后x和i都无法找到正确的内存位置,会发生报错
- 而在Closuer2中,没有报错:因为i没有发生变化,实际上这里是实际上的最终变量(effective final),该术语由Java 8 创建,其意思是我们虽然没有显式地将一个变量声明为最终变量,但是仍然可以用最终变量地方式看待它,只要不改变其值即可.
如果一个局部变量的初始值从不改变,它就是实际上的最终变量
public class Closure6 {
IntSupplier makeFun(int x) {
int i = 0;
i++;
x++;
final int iFinal = i;/*这里的final可以去掉,因之后未改变,已经构成"实际上的最终变量"*/
final int xFinal = x;
return () -> xFinal + iFinal;
}
}
-
如果非要使用变化的临时变量,我们可以用final变量进行中继
-
以上讨论都在基本类型中,下面讨论在对象中的情况
public class Closure8 {
Supplier<List<Integer>> makeFun() {
final List<Integer> ai = new ArrayList<>();/*这里的final可以去掉,因之后未改变,已经构成"实际上的最终变量"*/
ai.add(1);
return () -> ai;
}
public static void main(String[] args) {
Closure8 c7 = new Closure8();
List<Integer>
l1 = c7.makeFun().get(),
l2 = c7.makeFun().get();
System.out.println(l1);
System.out.println(l2);
l1.add(42);
l2.add(96);
System.out.println(l1);
System.out.println(l2);
}
}
/* Output:
[1]
[1]
[1, 42]
[1, 96]
*/
- 上述代码运行成功了,可能你们会感到疑惑,但这里需要提醒的是,对于final修饰的对象引用,说明该对象引用不能被重新赋值,所以该引用指向的对象是可以发生变化的,但不能被另一个新的对象赋值,所以Closure8中,ai的final去掉也不会出现问题,因为构成了"实际上的最终变量"
- 但是如果我们将ai重新赋值,就会出现问题,如下:
// 无法通过编译
import java.util.*;
import java.util.function.*;
public class Closure9 {
Supplier<List<Integer>> makeFun() {
List<Integer> ai = new ArrayList<>();
ai = new ArrayList<>(); // Reassignment
return () -> ai;
}
}
-
综上,lambda使用的变量
- 可以是"实际上的最终变量",即该变量不能被重新赋值,但是可以修改其指向的对象
- 也可以是某对象的一个字段,因为其有独立的生命周期,不需要任何的捕获,因此可以被lambda使用
-
内部类中的闭包,与高级函数类似,所以实际上,只要有内部类,就会出现闭包的概念(Java 8只是让闭包的实现变简单了). Java8之前没有"实际上的最终变量",都需要显式声明
13.7 函数组合
- 函数组合:将多个函数结合使用以创建新的函数,这是函数式编程的基本技术之一
- java.util.function提供的函数组合方法
andThen(argument):先执行原始操作,再执行参数操作compose(argument):先执行参数操作,再执行原始操作and(argument):对原始谓词和参数谓词执行逻辑与操作or(argument):对原始谓词和参数谓词执行逻辑或操作negate(argument):对所得谓词进行逻辑取反
f4 = f1.compose(f2).andThen(f3);//执行顺序:f2,f1,f3
f4 = f1.compose(f3).compose(f1).compose(f2);//执行顺序 f2,f1,f3,f1 倒序执行
f4 = f1.andThen(f3).andThen(f1).andThen(f2);//执行顺序 f1,f3,f1,f2 顺序执行
f4 = f1.andThen(f3).compose(f1).andThen(f2).compose(f2);//执行顺序 f2,f1,f1,f3,f2
13.8 柯里化和部分求值
- 柯里化(currying)是一种将具备多个参数的函数转换成一系列使用一个参数的函数的技术
- Java中实现:定义多层函数,每层函数都是单一参数,每层函数返回下一层函数,最后一层函数返回结果
public class CurryingAndPartials {
// 未柯里化:
static String uncurried(String a, String b) {
return a + b;
}
public static void main(String[] args) {
// 柯里化函数
Function<String, Function<String, String>> sum =
a -> b -> a + b;
System.out.println(uncurried("Hi ", "Ho"));
Function<String, String>
hi = sum.apply("Hi ");
System.out.println(hi.apply("Ho"));
// 应用
Function<String, String> sumHi =
sum.apply("Hup ");
System.out.println(sumHi.apply("Ho"));
System.out.println(sumHi.apply("Hey"));
}
}
/* Output:
Hi Ho
Hi Ho
Hup Ho
Hup Hey
*/
public class Curry3Args {//3个函数的柯里化
public static void main(String[] args) {
Function<String,
Function<String,
Function<String, String>>> sum =
a -> b -> c -> a + b + c;
Function<String,
Function<String, String>> hi =
sum.apply("Hi ");
Function<String, String> ho =
hi.apply("Ho ");
System.out.println(ho.apply("Hup"));
}
}
/* Output:
Hi Ho Hup
*/
13.9 纯函数式变成&13.10 总结
- 因为Java并不是不可变语言,所以我们需要仔细设计,让所有内容都是final的,确保方法和函数没有副作用
- lambda表达式和方法引用不是将Java变成函数式语言,而是提供了对函数式编程风格的更多支持
14 流
- 流的核心优点:使得程序更小,同时可以充分发挥lambda表达式和方法引用的威力
- 声明式编程:是一种编程风格,我们说明想要完成什么what,而不是指明怎么做how
- 流具有惰性求值:只有在绝对必要时才会被求值,这种方式可以避免不必要的计算,同时可以提高性能
14.1 Java8 对流的支持
- Java系列是需要保留之前的一切的,为此需要考虑如何将流加入库中,而不会破坏之前的代码
- 而问题的最大挑战在使用了接口的库,不能轻易给接口增加新方法,因为这会破坏之前的代码,所以Java8使用了默认方法来解决这个问题,将流方法添加到了接口中,但是这些方法都是默认方法,因此不会破坏之前的代码,方法可分为三种类型
- 创建流
- 修改流元素(中间操作)
- 消费流元素(终结操作):其意味着收集一个流的元素
14.2 流的创建
- 使用**Stream.of()**可以将一个条目变为一个流
- 每个Collection可以使用stream()方法生成一个流
- IntStream 类提供了一个 range() 方法,可以生成一个流—由 int 值组成的序列
for(int i : range(10, 20).toArray()) result += i;
- **generate()**方法是Java 8中Stream API中的一个方法,它用于生成一个无限的、连续的Stream。
- 具体来说,generate()方法接收一个Supplier接口类型的参数,这个参数是一个无限循环的生产者,它会不断地生产出一个新的元素,并将其放入Stream中
- 我们可以通过limit限制产生个数
public class Generator implements Supplier<String> {
Random rand = new Random(47);// 设置随机种子
char[] letters =
"ABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray();
@Override public String get() {
return "" + letters[rand.nextInt(letters.length)];//返回限制的数字大小
}
public static void main(String[] args) {
String word = Stream.generate(new Generator())
.limit(30)//限制个数
.collect(Collectors.joining());
System.out.println(word);
}
}
/* Output:
YNZBRNYGCFOWZNTCQRGSEGZMMJMROE
*/
- iterate():Stream.iterate()从第一个参数开始,然后将其传给第二个参数引用的方法,结果被添加到流上,并且保存下来作为下一次 iterate()调用的第一个参数,以此类推
- 例子:生成FIB数列
public class Fibonacci {
int x = 1;
Stream<Integer> numbers() {
return Stream.iterate(0, i -> {
int result = x + i;
x = i;
return result;
});
}
public static void main(String[] args) {
new Fibonacci().numbers()
.skip(20) // 跳过前20个
.limit(10) // 取10个
.forEach(System.out::println);
}
}
/* Output:
6765
10946
17711
28657
46368
75025
121393
196418
317811
514229
*/
- 流生成器:生成器设计模式中,创建一个生成器对象,为其提供多段构造信息,最后执行"生成"动作
public class FileToWordsBuilder {
Stream.Builder<String> builder = Stream.builder();//创建一个builder,可以向其中添加对象
public FileToWordsBuilder(String filePath)
throws Exception {
Files.lines(Paths.get(filePath))
.skip(1) // 跳过第一行
.forEach(line -> {
for(String w : line.split("[ .?,]+"))
builder.add(w);
});
}
Stream<String> stream() { return builder.build(); }
public static void
main(String[] args) throws Exception {
new FileToWordsBuilder("Cheese.dat").stream()
.limit(7)
.map(w -> w + " ")
.forEach(System.out::print);
}
}
- Arrays类使用stream()是可以指定流的区间
- 下面代码中,选择区间[3,6) 进行输出
Arrays.stream(new int[] { 1, 3, 5, 7, 15, 28, 37 }, 3, 6)
.forEach(n -> System.out.format("%d ", n));
//output:7 15 28
14.3 中间操作
- 1 调试与跟踪:peek():用来辅助调试,允许查看流对象进行操作但不能不修改
class Peeking {
public static void
main(String[] args) throws Exception {
FileToWords.stream("Cheese.dat")
.skip(21)
.limit(4)
.map(w -> w + " ")
.peek(System.out::print)
.map(String::toUpperCase)
.peek(System.out::print)
.map(String::toLowerCase)
.forEach(System.out::print);
}
}
/* Output:
Well WELL well it IT it s S s so SO so
*/
- 2 对流元素及逆行排序:sorted():进行排序,同时也有接收Comparator参数,或函数引用的sorted类型
public class SortedComparator {
public static void
main(String[] args) throws Exception {
FileToWords.stream("Cheese.dat")
.skip(10)
.limit(10)
.sorted(Comparator.reverseOrder())
.map(w -> w + " ")
.forEach(System.out::print);
}
}
- 3 移除元素
- distinct():移除流中的重复元素
- filter(Predicate):保留符合条件的元素,也就是传给参数(即过滤函数),结果未true的元素
public class Prime {
public static boolean isPrime(long n) {
return rangeClosed(2, (long)Math.sqrt(n))//左闭右闭
.noneMatch(i -> n % i == 0);
}
public LongStream numbers() {
return iterate(2, i -> i + 1)
.filter(Prime::isPrime);
}
public static void main(String[] args) {
new Prime().numbers()
.limit(10)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
new Prime().numbers()
.skip(90)
.limit(10)
.forEach(n -> System.out.format("%d ", n));
}
}
/* Output:
2 3 5 7 11 13 17 19 23 29
467 479 487 491 499 503 509 521 523 541
*/
-
4 将函数应用于每个流元素
- map(Function):将Function应用于每个元素,并将结果放入流中
- mapToInt(ToIntFunction):同上,不过结果放在一个 IntStream 中
- mapToLong(ToLongFunction):同上,不过结果放在一个 LongStream 中
- mapToDouble(ToDoubleFunction):同上,不过结果放在一个 DoubleStream 中。
-
5 在应用map期间使用组合流:map函数生成的是一个流,我们有时需要将流展开为元素
- flatMap(Function):当Function生成为一个流时使用
- flatMapToInt(ToIntFunction):同上,不过结果放在一个 IntStream 中
- flatMapToLong(ToLongFunction):同上,不过结果放在一个 LongStream 中
- flatMapToDouble(ToDoubleFunction):同上,不过结果放在一个 DoubleStream 中。
public class StreamOfStreams {
public static void main(String[] args) {
Stream.of(1, 2, 3)
.map(i -> Stream.of("Gonzo", "Kermit", "Beaker"))
.map(e-> e.getClass().getName())
.forEach(System.out::println);
}
}
/* Output:
java.util.stream.ReferencePipeline$Head
java.util.stream.ReferencePipeline$Head
java.util.stream.ReferencePipeline$Head
*/
public class FlatMap {
public static void main(String[] args) {
Stream.of(1, 2, 3)
.flatMap(
i -> Stream.of("Gonzo", "Fozzie", "Beaker"))
.forEach(System.out::println);
}
}
/* Output:
Gonzo
Fozzie
Beaker
Gonzo
Fozzie
Beaker
Gonzo
Fozzie
Beaker
*/
14.4 Optional
-
标准流操作会返回一个Optional对象,因为它们不能确保所要的结果一定存在。这些流操作列举如下。
- findFirst():返回包含第一个元素的Optional对象,如果流为空则返回Optional.empty()
- findAny():返回包含任意元素的Optional对象,如果流为空则返回Optional.empty()
- max(),min():返回包含最大值或最小值的Optional对象,如果流为空则返回Optional.empty()
- reduce():使用BinaryOperator和Optional组合起来,将流中的元素反复结合起来,得到一个值,返回包含该值的Optional对象,如果流为空则返回Optional.empty()
- 例子
OptionalInt reduced = IntStream.range(0, 10) .reduce((a, b) -> a + b); System.out.println(reduced.getAsInt()); - average():对于数值化的流 IntStream、LongStream 和DoubleStream,average() 操作将其结果包在一个 Optional 中,以防流为空的情况
-
空流使用
Stream.<String>empty()创建
14.4.1 便捷函数
- 便捷函数用于或去Optional中的数据,简化了"先检查再处理所包含对象"的过程
- ifPresent(Consumer):如果Optional对象包含值,则对该值调用Consumer,否则不进行任何操作
- orElse(other):如果Optional对象包含值,则返回该值,否则返回other
- orElseGet(Supplier):如果Optional对象包含值,则返回该值,否则返回Supplier获得的值
- orElseThrow(Supplier):如果Optional对象包含值,则返回该值,否则抛出由Supplier 继续生成的异常
public class Optionals {
static void basics(Optional<String> optString) {
if(optString.isPresent())
System.out.println(optString.get());
else
System.out.println("Nothing inside!");
}
static void ifPresent(Optional<String> optString) {
optString.ifPresent(System.out::println);
}
static void orElse(Optional<String> optString) {
System.out.println(optString.orElse("Nada"));
}
static void orElseGet(Optional<String> optString) {
System.out.println(
optString.orElseGet(() -> "Generated"));
}
static void orElseThrow(Optional<String> optString) {
try {
System.out.println(optString.orElseThrow(
() -> new Exception("Supplied")));
} catch(Exception e) {
System.out.println("Caught " + e);
}
}
static void test(String testName,
Consumer<Optional<String>> cos) {
System.out.println(" === " + testName + " === ");
cos.accept(Stream.of("Epithets").findFirst());
cos.accept(Stream.<String>empty().findFirst());
}
public static void main(String[] args) {
test("basics", Optionals::basics);
test("ifPresent", Optionals::ifPresent);
test("orElse", Optionals::orElse);
test("orElseGet", Optionals::orElseGet);
test("orElseThrow", Optionals::orElseThrow);
}
}
/* Output:
=== basics ===
Epithets
Nothing inside!
=== ifPresent ===
Epithets
=== orElse ===
Epithets
Nada
=== orElseGet ===
Epithets
Generated
=== orElseThrow ===
Epithets
Caught java.lang.Exception: Supplied
*/
14.4.2 创建Optional
- 要自己编写生成Optional的代码时,有以下三种静态方法可以使用
- empty():生成一个空的Optional对象
- of(value):将一个非空值包装到Optional里,如果值为空,则抛出NullPointerException异常
- ofNullable(value):如果不知道这个 value 是不是 null,使用这个方法。如果value 为 null,它会自动返回 Optional.empty,否则会将这个 value 包在一个Optional 中
class CreatingOptionals {
static void
test(String testName, Optional<String> opt) {
System.out.println(" === " + testName + " === ");
System.out.println(opt.orElse("Null"));
}
public static void main(String[] args) {
test("empty", Optional.empty());
test("of", Optional.of("Howdy"));
try {
test("of", Optional.of(null));
} catch(Exception e) {
System.out.println(e);
}
test("ofNullable", Optional.ofNullable("Hi"));
test("ofNullable", Optional.ofNullable(null));
}
}
/* Output:
=== empty ===
Null
=== of ===
Howdy
java.lang.NullPointerException
=== ofNullable ===
Hi
=== ofNullable ===
Null
*/
14.4.3 Optional对象上的操作
-
有三种方法支持对Optional进行事后处理,数值化的Optional没有以上操作
- map(Function):如果Optional对象包含值,则对该值执行提供的mapping函数调用,返回一个Optional对象;否则返回Optional.empty()
- flatMap(Function):和 map() 类似,但是所提供的映射函数会将结果包在 Optional中,这样 flatMap() 最后就不会再做任何包装了
- filter(Predicate)::将 Predicate 应用于 Optional 的内容,并返回其结果。如果Optional 与 Predicate 不匹配,则将其转换为 empty。如果 Optional 本身已经是empty,则直接传回。
-
filter操作:对于普通流的filter操作,如果Predicate返回false,会将元素从流中删除;但是对于Optional的filter操作,如果Predicate返回false,会将Optional变为Optional.empty
class OptionalFilter {
static String[] elements = {
"Foo", "", "Bar", "Baz", "Bingo"
};
static Stream<String> testStream() {
return Arrays.stream(elements);
}
static void
test(String descr, Predicate<String> pred) {
System.out.println(" ---( " + descr + " )---");
for(int i = 0; i <= elements.length; i++) {
System.out.println(
testStream()
.skip(i)
.findFirst()
.filter(pred));
}
}
public static void main(String[] args) {
test("true", str -> true);
test("false", str -> false);
test("str != \"\"", str -> str != "");
test("str.length() == 3", str -> str.length() == 3);
test("startsWith(\"B\")",
str -> str.startsWith("B"));
}
}
/* Output:
---( true )---
Optional[Foo]
Optional[]
Optional[Bar]
Optional[Baz]
Optional[Bingo]
Optional.empty
---( false )---
Optional.empty
Optional.empty
Optional.empty
Optional.empty
Optional.empty
Optional.empty
---( str != "" )---
Optional[Foo]
Optional.empty
Optional[Bar]
Optional[Baz]
Optional[Bingo]
Optional.empty
---( str.length() == 3 )---
Optional[Foo]
Optional.empty
Optional[Bar]
Optional[Baz]
Optional.empty
Optional.empty
---( startsWith("B") )---
Optional.empty
Optional.empty
Optional[Bar]
Optional[Baz]
Optional[Bingo]
Optional.empty
*/
- flatMap操作:适用函数必须已经包装在Optional中,否则会报错
static void test(String descr,
Function<String, Optional<String>> func) {
System.out.println(" ---( " + descr + " )---");
for(int i = 0; i <= elements.length; i++) {
System.out.println(
testStream()
.skip(i)
.findFirst()
.flatMap(func));
}
}
14.4.4 由Optional组成的流
- 下面代码中实现了一个Optional的流,并展示如何从中得到值(使用get()函数)
public class Signal {
private final String msg;
public Signal(String msg) { this.msg = msg; }
public String getMsg() { return msg; }
@Override public String toString() {
return "Signal(" + msg + ")";
}
static Random rand = new Random(47);
public static Signal morse() {
switch(rand.nextInt(4)) {
case 1: return new Signal("dot");
case 2: return new Signal("dash");
default: return null;
}
}
public static Stream<Optional<Signal>> stream() {
return Stream.generate(Signal::morse)
.map(signal -> Optional.ofNullable(signal));
}
}
public class StreamOfOptionals {
public static void main(String[] args) {
Signal.stream()
.limit(10)
.forEach(System.out::println);
System.out.println(" ---");
Signal.stream()
.limit(10)
.filter(Optional::isPresent)
.map(Optional::get)
.forEach(System.out::println);
}
}
/* Output:
Optional[Signal(dash)]
Optional[Signal(dot)]
Optional[Signal(dash)]
Optional.empty
Optional.empty
Optional[Signal(dash)]
Optional.empty
Optional[Signal(dot)]
Optional[Signal(dash)]
Optional[Signal(dash)]
---
Signal(dot)
Signal(dot)
Signal(dash)
Signal(dash)
*/
14.5 终结操作
- 将流转换为一个数组
- toArray():将流转换为一个数组,如果流为空,返回一个长度为0的数组
- toArray(generator):返回一个由generator函数生成的数组
- 在每个流元素上应用某个终结操作
- forEach(Consumer):对每个元素应用Consumer函数(可以以任何顺序操作元素,但只有在引入多cpu运行时才有效)
- forEachOrdered(Consumer):对每个元素应用Consumer函数,并且按照原始流顺序执行
public class ForEach {
static final int SZ = 14;
public static void main(String[] args) {
rands().limit(SZ)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
rands().limit(SZ)
.parallel()
.forEach(n -> System.out.format("%d ", n));
System.out.println();
rands().limit(SZ)
.parallel()
.forEachOrdered(n -> System.out.format("%d ", n));
}
}
/* Output:
258 555 693 861 961 429 868 200 522 207 288 128 551 589
551 589 861 555 288 128 429 207 693 200 258 522 868 961
258 555 693 861 961 429 868 200 522 207 288 128 551 589
*/
- 收集操作
- collect(Collector):将流中的元素收集到一个容器中
.collect(Collectors.toCollection(TreeSet::new));
- collect(Supplier, BiConsumer, BiConsumer):和上面类似,但是Supplier 会创建一个新的结果集合,第一个 BiConsumer 是用来将下一个元素包含到结果中的函数,第二个 BiConsumer 用于将两个值组合起来(较少用到 )
- 组合所有流元素
- reduce(BinaryOperator):使用 BinaryOperator 来组合所有的流元素。因为这个流可能为空,所以返回的是一个 Optional
- reduce(identity, BinaryOperator):和上面一样,但是将 identity 用作这个组合的初始值。因此,即使这个流是空的,我们仍然能得到 identity 作为结果
class Frobnitz {
int size;
Frobnitz(int sz) { size = sz; }
@Override public String toString() {
return "Frobnitz(" + size + ")";
}
// 生成器:
static Random rand = new Random(47);
static final int BOUND = 100;
static Frobnitz supply() {
return new Frobnitz(rand.nextInt(BOUND));
}
}
public class Reduce {
public static void main(String[] args) {
Stream.generate(Frobnitz::supply)
.limit(10)
.peek(System.out::println)
.reduce((fr0, fr1) -> fr0.size < 50 ? fr0 : fr1)
.ifPresent(System.out::println);
}
}
- 上述代码中,reduce()方法中使用了lambda表达式,其中fr0表示上次调用reduce()时的结果,第二个fr1是当前来自流中的新值.
- 所以在第一次调用reduce()时,会返回Optional.empty(),因此需要使用ifPresent()来检查是否有值
- 匹配
- anyMatch(Predicate):如果流中的任何一个元素成功匹配 Predicate,返回 true,遇到第一个true就会返回
- allMatch(Predicate):如果流中的所有元素都成功匹配 Predicate,返回 true,遇到第一个false就会返回
- noneMatch(Predicate):如果流中的所有元素都不成功匹配 Predicate,返回 true,遇到第一个true就会返回
- 选择一个元素
- findFirst():返回流中的第一个元素的 Optional,如果流为空则返回 Optional.empty
- findAny():返回流中的任意元素的 Optional,如果流为空则返回 Optional.empty,findAny对于非并行的流也会选择第一个
- 如果要选择流的最后一个元素,可以使用reduce()方法
Stream.of("one", "two", "three").reduce((n1, n2) -> n2);
- 获得流相关的信息
- count():返回流中元素的个数
- max(Comparator):返回流中最大值
- min(Comparator):返回流中最小值
- 数值化流的信息
- average():返回流中元素的平均值
- sum():返回流中元素的总和
- summaryStatistics():返回一个包含流中元素各种统计值的对象,如最大值,最小值,平均值,总和,个数
14.6 小结
- 流改变Java编程的本质,带来了极大的提升
- 同时防止了很多Java程序员转向Kotlin和Scala等函数式的JVM语言