使用不变量在回归测试和错误定位 2024-03-22 Using automatically generated invariants for regression testing and bug localization
引用:Sagdeo P, Ewalt N, Pal D, et al. Using automatically generated invariants for regression testing and bug localization[C], 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2013: 634-639.
CCF A ASE
链接
1 介绍
在软件开发和部署后,检测和定位软件中的错误行为都是具有挑战性的。在这项工作中,我们提出了一种新颖的方法来解决这一挑战,即在软件开发生命周期的不同阶段使用自动生成的程序不变量
我们在[1]种提出了PRECIS,一种不变量自动生成技术,其实用静态路径信息来引导静态分析,以生成程序不变量。其比[2,3,4]不变量生成技术好,因其表达性,覆盖度和扩展度
PRECIS对分支点(if/else和switch)语句的谓词值进行插桩,以收集关于程序或函数控制流结构如何影响其行为的动态信息。然后PRECIS利用程序执行期间收集的跟踪数据,动态推断谓词值与函数输入/输出之间的统计显著关系。如论文中的实验结果所示,PRECIS谓词的假阳性率低于10%
在本文工作中,我们将PRECIS自动化为一键式工具。我们提出了其在软件开发生命周期的不同阶段两个新颖而重要的应用
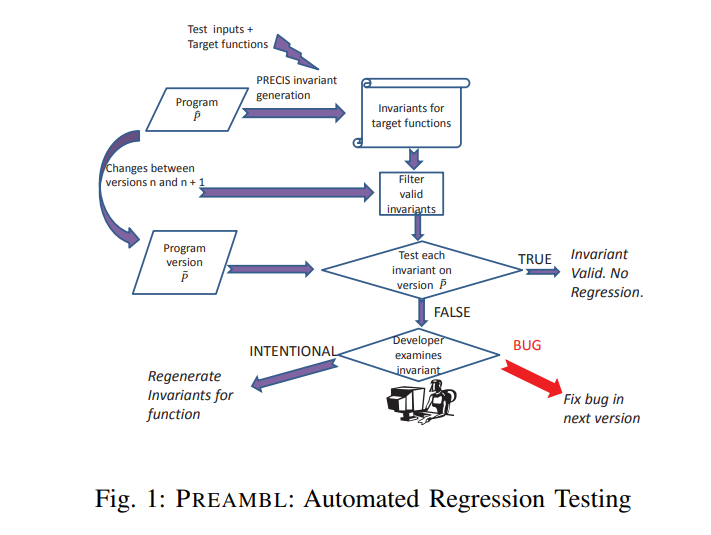
我们将驱动PRECIS谓词和不变量应用的总体技术称为PREAMBL。
Regression Testing
回归测试通常通过创建一组测试用例和期望输出来完成,这些测试用例涵盖了程序的预期行为[7],[8]。 用来测试在原本程序种正确运行的功能,在新版本中依旧可以正常运行
通过PREAMBL,我们介绍了使用不变量进行回归测试的概念。不变量总结了程序的关键功能。而单个测试用例捕获一个程序执行,每个不变量可以捕获多个执行的预期行为,因此,验证不变量的有效性可能比传统测试更全面。
不变量旨在为输入/输出等价性的传统回归测试提供功能/行为检查的补充。
然而,不变量进行回归测试的权衡是,与测试不同,其不易跨版本移植。因此我们提出了方法的原则是,原始程序的不变量应该在新版本种也成立,为此需要检查从原始版本种获得的不变量是否还能适用新的版本
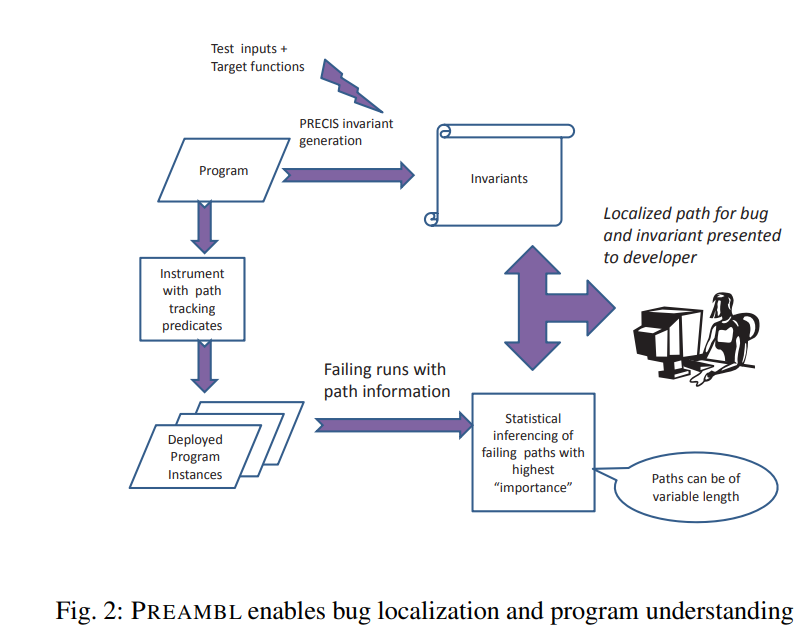
Bug Localization
识别程序中的错误是调试种耗时的部分。
断言检查通常由于性能原因在软件发布时从程序中移除。因此,与其将断言集成到发布代码中,PREAMBL对程序的分支点进行轻量级插桩,以定位错误
部署后错误定位和分析的愿景如图2所示. 如果程序无法产生正确的输出,导致失败的分支点序列将用于识别最有可能导致失败的程序路径。通过统计分析确定了与失败高度相关的程序子路径。
与[12,9]类似,PREAMBL统计分析考虑了在路径上发生的总失败的比例及通过该路径的执行中导致失败的百分比。PREAMBL分析构建了一个路径频率树来识别最大重要性的子路径,使得PREAMBL能够确定与失败高度相关的可变长度子路径。而以往工作只推导了单个函数的固定长度路径,PREAMBL允许在大型函数中进行增强的定位,适用于高度局部化的错误以及根本原因跨越多个函数的错误。
2 不变量生成
PRECIS[1]对输入,输出,谓词进行插桩
执行跟踪数据由输入,谓词,输出具体值得元组组成
使用上述数据通过谓词聚类的过程生成不变量,详见论文[1]
本工作中,扩展[1],以处理更复杂的控制和数据流结构
Multiple Output Variables:
Function calls:
Loops:
Arrays and pointers:
实现:PRECIS插桩程序使用Fjalar[13],基于Valgrind,最初支持Daikon的不变量生成。
3 使用PRECIS不变量的回归测试
如果在 P o r i g P_{orig} P or i g P n o w , P f u t u r e P_{now},P_{future} P n o w , P f u t u re
首先,由于程序新版中谓词变化不大,因此使用程序代码的字符串文字匹配,将新旧版本的谓词进行匹配,创建映射
当谓词在版本间发生变化时,PRECIS可以通过程序员提供的注释来描述背后的意图
我们描述了映射不变式导致的三种情况,具体却决于将他们纳入新版本所需的程序员的工作程度
情况1:不变量在两个版本间完全自动映射(需满足所有谓词都可以自动映射)
情况2:不变式需要一些程序员的努力才能在新版本中有效。这可能是由于需要为谓词添加注释或输入或输出变量名称更改
情况3:不变式无法在版本之间映射,这是由于基本代码发生了变化。
我们将在第5节讨论每种情况出现的频率及所得到的覆盖率
接下来将展示案例研究,展示了使用PRECIS生成的不变量进行回归测试的PREAMBL的有效性
A. Case Study
下图展示了一个假设的科学计算应用中函数convert_units的实现。
接受三个参数,value表示测量值,src表示传递值的单位,tgt表示要转换为的单位。
返回值是将输入值转换为目标单位的相应值。该函数设置了检查,以捕获整数溢出的情况,以及捕获不支持的转换。在这两种情况下,函数都返回-1,被视为无效值。
当在convert_units上运行PRECIS时,捕获到以下不变量:
(1)(p0 = 1 ∧ p1 = 0) ⇒ (result = 36 × val)
(2)(p0 = 1 ∧ p1 = 1) ⇒ (result = −1)
(3)(p0 = 0 ∧ p1 = X) ⇒ (result = −1)
假设开发人员重写了代码,使其更通用,如图所示,将YD_TO_IN定义为35。当开发人员运行测试套件时,不变量(1)将触发,因为当第一个if语句被执行而第二个if语句未执行时,结果不是36 × val。这迅速提醒开发人员代码中的错误。
更重要的是,与仅比较应用程序输出值不同,失败的断言还明确告知开发人员特定的上下文(在本例中,是没有溢出的yd. to in.转换),在这种上下文中函数输出(在本例中是convert_unit的结果)出现问题。这有助于开发人员快速有效地隔离错误。
4 使用PRECIS不变量的错误定位
PREAMBL捕获程序路径信息,通过对控制流分支点(如if语句,case语句等)进行插桩作为谓词。因此,谓词对应于控制流图(CFG)中的节点,谓词的值通过的图的方向。
对于一个程序运行,一些列谓词及其值表示了程序中经过的路径。本文中,使用格式 p 0 = v 0 ) ⇒ ⋅ ⋅ ⋅ ⇒ ( p n − 1 = v n − 1 ) p0 = v0) ⇒ · · · ⇒ (pn−1 = vn−1) p 0 = v 0 ) ⇒ ⋅⋅⋅ ⇒ ( p n − 1 = v n − 1 ) v 0 = 1 v0 = 1 v 0 = 1 p 0 p0 p 0 v 0 = 0 v0 = 0 v 0 = 0 p n − 1 pn−1 p n − 1 v n − 1 vn−1 v n − 1
每个这样的序列都标记为“成功”(生成期望的输出)或“失败”(未生成期望的输出),取决于给定程序执行的结果。
为了定量评估路径,PREAMBL使用了 [10]提出[9]也是用的算法。该算法中,我们为每个路径 p p p
S e ( p ) S_e(p) S e ( p ) F e ( p ) F_e(p) F e ( p ) S o ( p ) S_o(p) S o ( p ) F o ( p ) F_o(p) F o ( p ) 如果所有构成路径的谓词都评估为其指定的值,则认为该路径已执行; 如果路径中的第一个谓词被评估,都视为已被观察到。
利用这些测量值和F,即总失败运行次数。我们计算4个分数来定量判断路径上有bug的指示程度。然而路径运行失败不一定是bug,也可能是几个错误的谓语造成的路径运行失败
S e n s i t i v i t y ( p ) = l o g ( F e ( p ) ) / l o g ( F ) Sensitivity(p) = log(F_e(p))/log(F) S e n s i t i v i t y ( p ) = l o g ( F e ( p )) / l o g ( F ) C o n t e x t ( p ) = F o ( p ) / ( F o ( p ) + S o ( p ) ) Context(p) = F_o(p)/(F_o(p)+S_o(p)) C o n t e x t ( p ) = F o ( p ) / ( F o ( p ) + S o ( p )) I n c r a s e ( p ) = F e ( p ) / ( F e ( p ) + S e ( p ) ) − C o n t e x t ( p ) Incrase(p) = F_e(p)/(F_e(p)+S_e(p)) - Context(p) I n cr a se ( p ) = F e ( p ) / ( F e ( p ) + S e ( p )) − C o n t e x t ( p ) I m p o r t a n c e ( p ) = 2 1 / I n c r e a s e ( ) p + 1 / S e n s i t i v i t y ( p ) Importance(p) = \frac{2}{1/Increase()p} + 1/Sensitivity(p) I m p or t an ce ( p ) = 1/ I n cre a se ( ) p 2 + 1/ S e n s i t i v i t y ( p )
PREAMBL 的目标是辨识出对bug敏感的路径。如,该路径与多个失败的运行相关。
然而,我们还希望具有特异性,即在许多成功运行中,没有被预测失败的路径
在信息检索中,结合specificity和sensitivity的标准方法是计算它们的谐波平均,因为这种度量优先考虑两个维度中的高分。度量指标 I m p o r t a n c e ( p ) Importance(p) I m p or t an ce ( p )
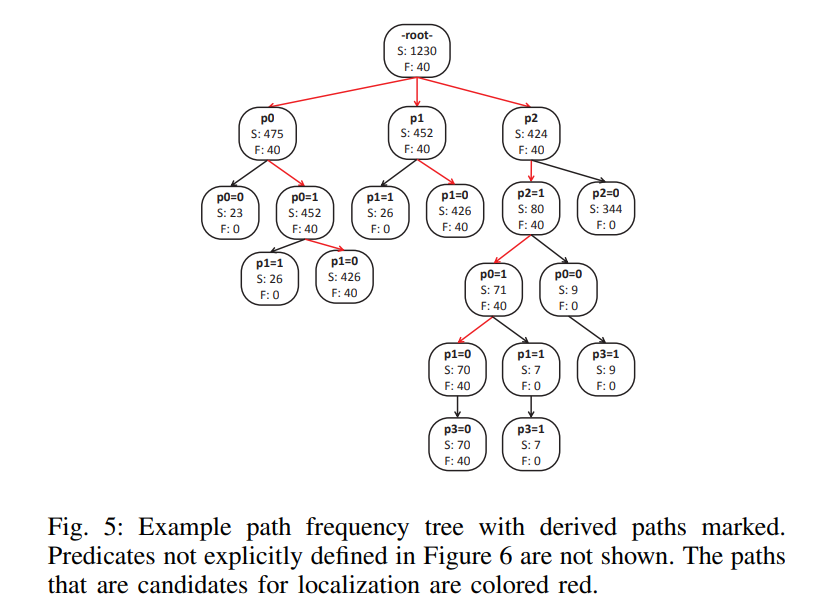
A. building the Path Frequency Tree
PREAMBL为有效计算 variable-length paths,需快速决定 S e , F e , S o , F o S_e,F_e,S_o,F_o S e , F e , S o , F o
每个路径频率树 T p i T_{p_{i}} T p i p i p_i p i F e ( p ) F_e(p) F e ( p ) S e ( p ) S_e(p) S e ( p )
路径频率树中的每个节点表示程序路径中单个谓词 (pk = vk) 的值。
节点的父节点是路径中紧接在节点之前的谓词值。 每个子节点代表当前节点后续直接执行的谓词值
当我们从跟踪文件数据中读取每个执行路径时,我们在给定路径的树上遍历时在每个节点上递增 S e ( p ) S_e(p) S e ( p ) F e ( p ) F_e(p) F e ( p )
此外,我们根据执行成功或失败递增了树级别的 S o ( p ) S_o(p) S o ( p ) F o ( p ) F_o(p) F o ( p )
查找路径(px = vx) ⇒ (py = vy) ⇒ … ⇒ (pz = vz)的这些值,PREAMBL首先会找到px的路径频率树。
然后,我们从根节点px = vx的子节点开始遍历树,直到到达对应于pz = vz的节点为止。
此节点上存储的Se§和Fe§值将指示路径在成功和失败运行中分别执行的次数。我们可以使用这些值以及存储在根节点处的So§和Fo§来计算路径的Increase、Sensitivity和Importance。
生成路径频率树的计算复杂度为O(n × l^2),其中n是捕获的路径数,l是这些路径的最大长度。在实践中,PREAMBL分析所有测试应用程序所需的时间不到一分钟。
B. Generating High-importance Sub-paths
建立好频率树后,我们遍历树寻找最大Importance路径
具体来说
对于每个节点,我们计算Increase§。对于Increase < 0的路径相应的节点,我们立即丢弃。
其他的则被添加到一个优先级队列中,该队列按照它们的Importance分数进行排序。
这个过程持续进行,直到所有路径频率树都被完全分析。
在这一点上,可以从优先级队列中查询出前几个结果。
这个过程的最坏时间复杂度是O(n log(n)),其中n是捕获的不同路径数。
C. Mapping Bugs to Invariants
高分的路径可以告诉程序员可能出现bug的路径,但也不一定有。
因此,PREAMBL将此错误定位信息联系到不变量。这些不变量将总结出希望的输出行为,这将允许用户比起重看代码更容易的理解代码在做什么
此外,由于生成的不变式是路径特定的,因此只显示与失败路径相关的特定不变式。如果不变式捕获了不良行为,那么以不变式的形式对行为进行总结可能会使开发人员更容易识别实现中的问题。
D. Case Study
现在假设图4中错误已被修复,现在存在一个新函数,如下图,handle_input()将一个长整数,而不是一个整数传递给要转换的值。然而当值足够大的时候,long转int会移除,产生错误,接下来我们将展示如何使用PREAMBL来定位这个错误
当运行PREAMBL时,首先构建以可路径树,该村了成功和失败执行中每个执行路径的频率。如下图示,此时与错误高度相关的路径是(p2 = 1) ⇒ (p0 = 1) ⇒ (p1 = 0),这准确匹配了bug在convert_units从if语句p2中调用并执行有效的非溢出转换时出现的观察结果
在这个例子中,为convert_units()生成的不变量是(p0 = 1 ∧ p1 = 0) ⇒ (result == 36 × result)。由于这个不变量描述了bug路径上result的行为,其与bug关联在一起呈现给开发人员。
因此,PREAMBL向开发人员展示了bug的本地化路径和相应的预期行为。
此时,她可能会立即注意到传递给convert_units的长整数和使用的整数类型之间的类型不匹配。
5 实验结果
为评估PREAMBL有效性,我们SIR[15]上进行了测试
我们使用SIR作为应用程序和bug的标准化存储库,以便与先前的bug检测工具进行比较[10],[9]。
A. Invariant Quality
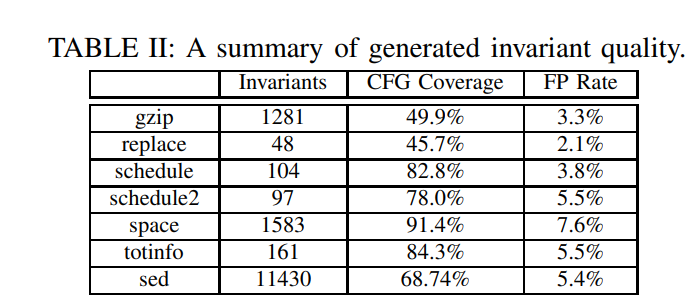
为检查PRECIS生成的应用程序的不变量的质量,我们对每个应用程序运行了测试套件的三分之一,生成了跟踪数据,并执行了谓词聚类导出不变量。
结果显示:生成的不变量数量与程序大小成比例增长,但即使对于大小相似的程序,变化也很大。我们发现这与每个程序的结构有关。
例如,sed.c这样大量使用全局变量的程序往往生成的不变量数量极高,因为函数输出的数量较多
我们将不变量的控制流图CFG覆盖率定义为 不变量触发的程序路径百分比
覆盖率在应用程序间差异很大,对于控制流导向型程序,其中数据流主要通过线性运算符描述,覆盖率最高。
还检查了不变量的虚假程度,具体来说,我们将不变量的假阳性率定义为PRECIS生成的不变量在一个测试集的三分之一上失效的百分比,而在运行完整的测试集时无效。PRECIS生成的不变量具有很低的假阳性率:在所有情况下都不到10%。
B. Regression Testing
我们使用每个应用程序buggy版本来回归测试
第一步是生成正确版本的不变量
然后对于每个buggy版本,映射不变量 谓语,输入和输出
为了评估不变量在检测回归方面的有效性,我们运行测试套件同时检查生成的不变量。如果在测试运行期间任何不变量求值为假,则我们已经检测到了回归。
对于不同的程序,检测覆盖率差异很大,如果程序控制流发生显著变化,检测覆盖率明显下降
此外,如果不变量是对指针密集算术的程序生成的,你们不变量将生成在指针的第一个元素上,如果对指针的第二个元素或其他元素进行更改,则检测覆盖率会降低。原则上,可以为所有指针元素生成不变量,但这将导致不变量生成的高开销。
C. Bug Localization
我们评估了PREAMBL使用的基于路径的定位计数的有效性,并测量了可以与不变量信息相关联的局部化错误百分比。为此,我们测量了这些错误中有多小可以定位到特定的子路径,并提供了关于这些子路径特异性的综合信息。
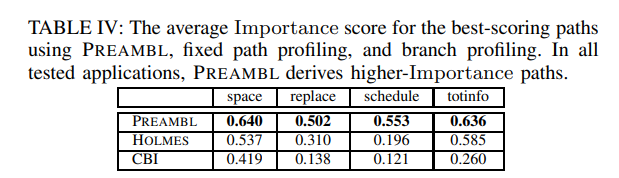
具体而言,我们将PREAMBL与先前提出的分析方案进行分析:[9]中使用的固定长度的函数内路径和[11]中使用的简单的单分支分析方案。所有三种技术都通过前5个导出路径的平均重要性得分进行评分。
表IV显示了几个基准测试的汇总结果。在每种情况下,PREAMBL生成了更高分数的结果。直觉上,按照重要性§度量的定义,路径的更高分数意味着路径对错误的更好预测,因此更好的错误定位,这反过来又意味着开发人员的调试开销更少。与HOLMES和CBI相比,PREAMBL生成的路径的更高分数表明了改进的错误定位。
6 结论
我们提出了一种通过使用程序不变量将错误定位和回归测试结合起来的技术。
我们建议将程序调试从发布前和发布后的阶段分开,提出了一种流程,在这些阶段中产生的调试信息可以一起使用,以提高软件的可靠性。
个人总结
本文延续它们之前的工作[1],一个动态不变量探测方法,再次扩展,随后提出了PREAMBL,一个使用不变量进行回归测试和错误定位的方法
在回归测试中,使用不变量的失败作为回归的标志,需要进行不变量的映射(有时需要程序员的介入)
在错误定位中,使用路径频率树来统计路径的执行次数,通过计算路径的重要性来定位错误,随后将错误与不变量联系起来,以便开发人员更好的理解错误