The use of likely invariants as feedback for fuzzers
- 引用:Fioraldi A, D’Elia D C, Balzarotti D. The use of likely invariants as feedback for fuzzers[C], 30th USENIX Security Symposium (USENIX Security 21). 2021: 2829-2846.
- CCF A USENIX Security
- 链接
- 代码
0 摘要
动机
- 模糊测试已经被证明是发现程序漏洞的有效技术,但仍存在一些开放的挑战。
- 其中一个主要挑战是,广受欢迎的基于覆盖率引导的模糊测试会尽可能的将测试用例覆盖程序的不同部分,但仅仅考虑覆盖率可能并不能充分触发程序的漏洞。
- 在现实中,许多缺陷触发需要具体的程序状态,这不仅需要控制流的参与,还需要考虑一些程序变量的值。
- 然而不幸地,由于状态爆炸的原因,之前提出的探索程序状态的策略在现实中作用很小。
解决
- 在本文中,我们提出了一种新的反馈机制,通过考虑常量和程序变量间的关系来增强代码覆盖率。
- 基于这一目的,我们在基本块等级上对变量学习可能的不变量,然后相应的对程序状态进行切分。
- 我们的反馈可以辨别一个输入是否违反了一个或多个不变量并对此进行奖励,因此缩小了代码覆盖提供的对程序状态的估计。
- 我们在INVSCOV原型上实现了这一机制,该原型基于LLVM和AFL++开发。
- 我们的实验展示了我们的方法与完全使用代码覆盖作为反馈的fuzzer相比,可以找到更多不同的缺陷。
- 除此之外,我们的试验发现了每天在OSS-fuzzer测试的一个库上的两个漏洞,这两个漏洞在库的最新版本中仍然存在。
1 介绍
背景b
- fuzzing 成为发现软件漏洞的主要技术,其最初目的是随机生成非法或异常输入,以检测程序中的bug,如今的fuzzing经常依赖于一些启发式的方法来引导输入生成。
- 距今,Coverage-Guided Fuzzing(CGF)是最流行的fuzzing技术之一,其选择可以提升程序代码覆盖率的输入,一般为CFG的唯一路径的数量
- 随后,许多方法专注于克服CGF的限制,如
- 使用一些技术来解决复杂路径限制[82,66,7,69,5]
- 去除突变测试中非法的测试用例[65,59,3,6,28]
- 或者搜寻程序中更有前景的部分[58,57,9]
- 尽管这些方法减少了到达目标程序不同部分的时间,但需要理解的是,仅仅代码覆盖是发现bug的必要不充分条件。实际上,bug触发时,(1)程序运行到一个给定指令(2)程序状态满足特定状态。
- 一方面,因为使用代码覆盖率来奖励探索结果导致模糊测试器没有任何动机去探索更多已经观察到的控制流事实(例如,分支及其频率)的状态。因此,现有工具检测涉及对程序状态复杂约束的bug变得更加困难。
- 另一方面,简单地奖励模糊测试器探索新状态(状态覆盖率)也是一个不佳的策略,这通常会降低bug检测率。这是因为对于复杂的应用程序来说,程序状态爆炸
- 因此,需要特殊的技术来控制测试时程序的转该,同时保持fuzzer触发bug的能力,如今有一些工作想达到这种平衡。
- 一些fuzzer通过更敏感的反馈来近似程序状态,如使用调用堆栈信息或内存中加载和存储的值来丰富代码覆盖率。
- 另一些,如[79],除考虑控制流外,还有程序状态中的值,更好地近似了程序状态覆盖率,但在发现bug方面效率较低,因为其引发了状态爆炸
- 为了在避免状态爆炸的同时捕获更丰富状态信息,研究人员还研究了人工辅助的解决方案。
- 如FUZZ FACTORY [60]允许开发人员定义他们的领域特定目标,然后添加waypoints,当生成的测试用例朝这些目标取得进展时(例如,当两个比较操作数之间有更多的位相同),奖励模糊测试器。
- 在撰写本文时,目前最成功的程序状态覆盖的估计由一个仅由人类专家选择的程序点组成[4]。在这项工作中,状态空间部分手动标注,并且修改了反馈函数以更彻底地探索这样的空间。我们相信,这一过程的自动化是该领域的关键课题。
方法简介
- 本文中,我们提出了一个用于fuzzing的新反馈机制,在完全自动化的情况下,除了考虑代码覆盖率,还考虑了程序的一些有趣的部分,而且不会引发状态爆炸。
- 关键思想是,将边覆盖率–fuzzer使用最广泛和成功的代码覆盖率指标–与“usual”变量值的本地信息差相结合。
- 为此,我们通过执行输入语料库并学习所有观察到的执行的变量值和关系的约束来挖掘程序的可能的不变量。一个很重要的点是,基于执行的不变量挖掘产生的约束不一定模拟程序的属性,而是分析输入语料库的本地特征[25],因此,不同的输入可能违反约束
- 我们的直觉是,这些本地特征代表了程序状态的一个有趣抽象。因此,我们定义了一种新的反馈函数,当传入的基本块看到一个或多个违反可能不变量的变量值时,会对边进行不同处理。这种方法提升了CFG系统的灵活性,奖励探索代码覆盖率本身无法区分的程序状态。
- 我们开发了一组启发式方法来生成和细化不变量,并采用了有效的技术使得以很低的性能开销在程序中插装–这是一个很重要的指标。我们将它们实现为一个原型INVSCOV,基于LLVM[43],AFL++[30]
- 我们的实验设计了一组经常由其它fuzzer测试的程序,结果表明,我们的反馈机制可以简洁地考虑程序状态信息,除控制流外,还能发现比经典CFG方法更多,不同的漏洞
贡献
- 我们提出了一种新的反馈机制,用于fuzzing,它结合了代码覆盖率和程序状态的本地信息,而不会引发状态爆炸
- 一个我们方法的原型实现,叫INVSCOV,基于LLVM和AFL++
- 一个实验评估,展示了我们的方法与经典的上下文敏感的边覆盖比较
2 背景
2.1 程序属性和不变量
- 基于属性的测试是一种软件测试方法,其中程序属性某种形式规范驱动了测试过程,此类规范同时定义了哪些行为是有效的,并作为生成测试用例的基础。
- 正确性oracle可以嵌入到程序本身,以一组断言的形式出现来检查每个不变量的合法性[26].然后可以通过违反不变量断言来生成测试用例
- 由于将程序属性的识别委托给开发人员也是一个艰巨的任务,因此自动化一直是该领域探索的方向。在其它领域如内存错误检测[37],自动化不变量学习也是广泛探索的话题
- 可以通过静态代码分析来发现不变量
- RCORE[32]基于抽象解释[14]构建,并在运行时监控不变量,以检测来自内存错误的程序状态穗槐。通常,这样的不变量是可靠的,并且产生的误报有限
- 然而静态不变量分析固有的过度近似可能会产生过于粗糙的不变量,无法有效区分程序状态以进行高级分析
- 因此,一种更精确的发现不变量的方式,同时通过运行时检查程序状态,以更大数量的产生。因此,[35,24,61]中的方法是基于在执行期间动态收集的信息构建不变量的。
- 动态方法的缺点是,其产生的不变量是可能的不变量,即,对于分析的程序轨迹是成立的,单不适用于所有输入。因此,当学习到的不变量只捕捉到观察到的执行的局部属性时,可能产生误报
- 本文思想
- 在本工作中,我们将动态不变量的局部属性的问题转化为驱动fuzzer的优势。我们通过从测试用例语料库出发,像实际程序一样,该语料库无法满足所有的程序状态,然后我们修改fuzzer,使其对偏离初始语料库得到的不变量的行为更加敏感。此时,学习到的不变量捕捉到的时观察到的执行的属性,而不是程序本身的属性,这时我们用来生成更多样化的输入值集合的关键直觉
2.2 Fuzz Testing
- 思想:使用随机生成的测试用例反复测试程序,通常为非法或异常输入,以检测程序中的错误[62,50]
- 最朴素的fuzzing:不了解程序任何特征(例如,输入格式或程序执行情况),只提供随机输入。这对传统软件很有效[54]
- 近来有许多技术来提升朴素fuzzing的效率[50,62],我们可以根据以下原则对这些技术进行分组
-
- 需要了解程序信息的程度
-
- 生成测试用例的技术
-
- 搜索时用的反馈
-
- 根据第一个原则,我们可以将fuzzers分为三类
-
- White-box fuzzers:使用程序分析为程序构建完整图像。
- concolic executors like SAGE[33],SYMCC[66] 属于这类。然而,白盒测试分析消耗untenable[62],难以维持的。
-
- Black-box fuzzers:盲目地生成测试用例来测试。可以了解程序输入的格式,但不了解运行结果[80,52]
-
- Grey-box fuzzers:介于1,3之间,了解有限的信息通过轻量级的插桩,这些信息混合了程序分析和测试状态[62].一个例子是使用从测试用例中提取代码覆盖率如AFL[83],LIBFUZZER[46]
-
- 根据第二个原则,可分为 generational 和 mutational fuzzers
- 生成式模糊测试器从头开始创建新的测试用例,可以是随机的,也可以依赖于某种形式的格式规范,比如语法或领域特定语言。
- 突变式模糊测试器则通过对一组先前的测试用例进行突变来派生新的测试用例;这些突变可以是通用的、针对特定目标的,或者是由用户提供的或推断出的格式规范驱动的。
- 使用第三个原则,模糊测试器可以根据它们用于驱动探索的信息而进行划分,我们称之为feedback。
- coverage-based fuzzers:使用代码覆盖率作为搜索反馈
- 先前的研究表明,基于覆盖率的模糊测试器通常在发现漏洞方面要有效得多。由于还有其他形式的反馈可能存在,我们将更一般地将这种模糊测试设计称为反馈驱动的模糊测试。
Feedback-Driven Fuzz Testing
- 当一个CGF生成的测试用例触发了一个新的策划嗯需的部分时,其任务该测试用例 interesting 并将其添加到一个输入队列(称为种子)中,以供进一步处理。通过将这种技术与突变方法结合起来,我们获得了一个由代码探索驱动的进化算法。
- 代码覆盖率可以由不同的方法计算,例如仅考虑基本块,或者包括整个调用上下文[79]。
- 迄今为止,用于覆盖导向的模糊测试器最流行的标准是边覆盖,它最大化了程序函数控制流图(CFG)中访问的边的数量。像AFL这样的模糊测试器通过为边添加一个命中计数(即测试用例执行这些边的次数)来扩展纯边覆盖,以更好地近似程序状态。
- 最近,ANKOU进一步发展了这个想法,通过根据在线主成分分析的结果添加等效覆盖的测试用例到队列中,以考虑执行之间的命中计数差异。
- 如在2.2中所说,还有其它指标可以驱动fuzzer的演化。
- FUZZ FACTORY最近研究了几种替代方案,例如内存分配大小可以作为一种有用的反馈来暴露内存不足的漏洞,而比较指令的操作数中相同位的数量可以帮助绕过模糊测试的障碍。
- 简而言之,所有这些反馈技术都作为领域特定测试目标的捷径,代码覆盖并不是一个足够描述。
- 一个更一般的方法是,除了控制流外,数据流信息也代表了程序状态。迄今为止,我们所知道的最简单的实现就是“内存”反馈,其中来自内存加载和存储操作的每个新观察到的数据值被视为模糊测试器的新颖因素。不幸的是,这种解决方案很容易导致状态爆炸。
3 方法
- 本节,我们使用一个现实世界的漏洞展示我们方法的思想。
- 该漏洞是关于 libsndfile 中 WAV 文件格式解析的堆溢出,libsndfile 是一个用于操作音频文件的流行库。示例 1 和示例 2 显示了受影响的代码。具体而言,漏洞位于 ms_adpcm.c 文件中的 msadpcm_decode_block 函数中,在示例 2 中的第 9 行报告了此处的漏洞。

- 值得注意的是,我们在实验中使用的所有基于覆盖率导向的模糊测试器(§5)都能够到达代码中的脆弱点,但是却没有触发该漏洞。尽管易受影响的代码是“易于到达的”,并且 libsndfile 常常被用于模糊测试实验(包括 Google OSS-Fuzz 项目和最近的研究作品,比如 [31] 和 [81]),但是当我们运行实验时仍然存在漏洞。
- 这是因为,要触发漏洞,循环应该写入超出 pms->samples 指针所指内存范围之外的位置,而这个指针引用了 pms 结构末尾的 C99 变量大小数组字段。只有当程序处于特定状态时,才会发生这种情况,这种状态以 pms 缓冲区的分配大小较小(示例 1 中的第 8 行)和足够高的 pms->blocksize 值(示例 1 中的第 13 行)为特征,迫使循环写入数组的边界之外。
- 然而,这些要求都不能从代码覆盖中得出,因为程序中没有涉及这些阈值的分支。相反,其依赖于两个输入派生的值:blockalign 和 samplesperblock。
- CGF通常无法关心这种漏洞,因为没有引入新的覆盖率,并不会被视为一个有趣的测试用例
- 这展现了现代fuzzer探索程序状态时遇到的问题。
- 最先进的基于覆盖率导向的模糊测试系统在覆盖率上可能已经饱和,但仍然可能错过在其操作中触及的程序点上的漏洞。
- 此外,无法生成测试用例来覆盖未见过的程序点,当这些程序点不仅依赖于控制流可达时
3.1 Program State Partitions
- 本文的核心思想是,我们可以通过在处是输入语料库上执行测试用例从中学习可能的不变量,在应用程序代码的多个点将程序空间划分为不同的分区。
- 继续以我们的例子为例,假设我们可以使用标准的覆盖率导向模糊测试系统对 libsndfile 进行一定时间的模糊测试,比如 24 小时(我们将在第 3.4 节讨论不同语料库对提取的不变量的影响)。通过调查由模糊器保存的所有种子的变量值,我们将确定 init 函数的两个可能的不变量和易受攻击的解码循环的一个可能不变量。所有不变量都作为注释包含在示例 1 和 2 中。
- 这些不变量描述了由fuzzer生成的语料库产生的有限数量的状态。即,每个不变量都表示在测试实验期间fuzzer无法违反的程序状态条件,因此,我们的直觉是,我们可以使用这些不变量将程序状态划分为多个分区,如图1所示init函数
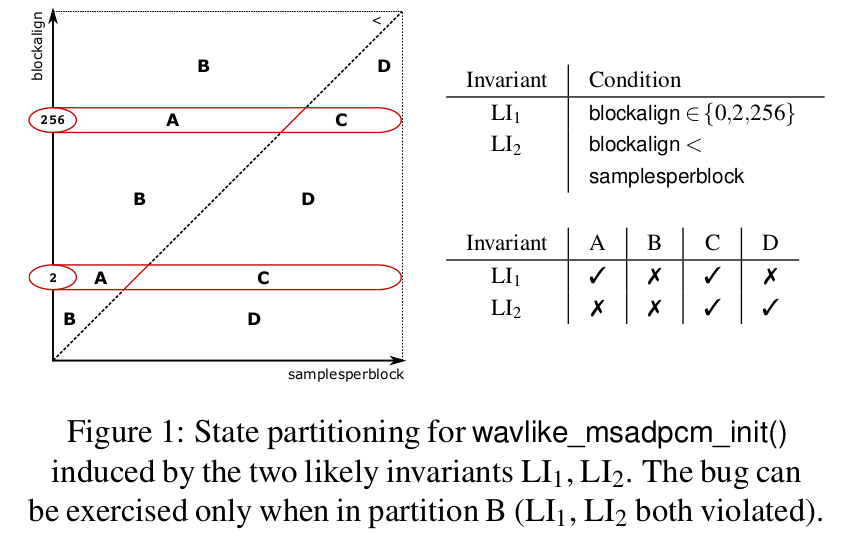
- 此时,我们可以看到这两个不变量将空间划分为四个不相邻的区域(图中的A到D区域),除第一个区域外,其它区域均未被fuzzer访问到。这些信息使得我们能够向fuzzer提供反馈,以探索新的状态。
- 此外,由于这些状态只能通过违反来达到,我们的直觉是其会将程序带入很少被探索的极端情况,此处漏洞可能长时间未被发现过
- 为捕获这些信息,本文提出的方法通过使用在基本块上学习到的可能不变量的违反情况来增强经典的边覆盖反馈。在理想情况下,我们可以学到精确的不变量,并将它们转化为代码覆盖的语句,而使纯覆盖率导向的模糊器能够接收反馈以向这些区域进展。然而,正如 §2.1 中描述的那样,当前的不变量挖掘技术会导致过度或不足的近似。
3.2 Using Invariants as Feedback
- 动态不变量检测的局限性在于,所得到的不变量通常更多地捕获了测试套件的局部属性,而不是程序的静态属性。然而,对于我们的目的来说,这恰恰是我们想要的。
- 事实上,只代表语料库的局部属性的可能不变量是有趣的,因为它们的违反会提示fuzzer程序状态中哪些值组合是不寻常的,理想情况下可能是漏洞所在。
- 因此,我们将基于不变量的反馈定义为边覆盖与源基本块中违反的可能不变量的信息的组合。
- 为了告知模糊器有趣的方向,我们调整了大多数基于覆盖的系统采用classic novelty search。
- 特别地,对于每个被CGF工具检测的控制刘边,我们使其为每个违反的可能不变量的唯一组合生成不同的novelty search。
- 正如4.2节详细介绍的,我们单独跟踪不变量并在每个基本块独立奖励它们:该选择带来了对程序状态分区,明确但又隐晦的编码。
- 不变量能够在不引发状态爆炸的情况下划分程序状态空间也是我们方法的关键见解之一。在每个基本块,N个不变量可以像N条非平行线一样局部地划分状态,将平面划分为N*(N+1)/2+1个区域。实践中,由于每个块通常只操作很少的变量,N为一个很低的值(附录A中的统计数据)
- 回到我们的例子,对于 wavlike_msadpcm_init 函数,我们有两个涉及到学习到的不变量的变量:blockalign 和 samplesperblock。触发漏洞的分区是 B——它同时违反了这两个不变量。我们的模糊器找到了一个值分配 {blockalign = 1280,samplesperblock = 8} 来触发漏洞。
- 通过基于不变量的反馈来增强敏感性,fuzzer可以分别违反每个不变量,保存这样的测试用例用于分区 A 和 D,并且还可以将这两个测试用例拼接起来生成一个将状态带到 B 的测试用例。更进一步说,我们的方法可以通过组合或变异先前的种子(每个违反一个或多个不同的不变量)来生成违反多个不变量的输入。
3.3 Pruning the Generated Checks
-
通过我们的示例,我们展示了我们如何使用不变量来划分程序状态,然后如何将此信息转变为反馈以驱动fuzzer探索。
-
然而,不是所有的不变量都有用:虽然拥有更多的不变量不会影响我们的方法论(即,探索更多分区不会失去敏感性),但其产生的额外状态会污染我们的反馈,过渡插桩也会影响运行时开销,因此,我们设计了三种修建方法来消除 哪些在其它可用信息光芒下 或 由于其它组成部分的特性 而检查起来毫无意义的不变量
-
- 第一种丢弃的不变量是不可能违反的不变量
- 如,无符号整数始终大于等于0,这对fuzzer没有意义
- 为了识别这些类似情况,我们针对被测程序的每个函数执行值范围分析[36]。最初,参数和全局存储是无约束的,分析为函数变量产生了适用于任何执行的边界。利用范围信息,我们指示我们的不变量挖掘器不要生成在逻辑上比静态发现的不变量更弱的可能不变量。由于这些不变量无法违反,我们可以节省监视它们所需的插桩成本。
-
- 第二类无用的不变量是那些结合不相关变量的
- 为了消除这些关系,我们为被测试程序的每个函数计算可比性集:每个变量仅属于一个这样的集合,并且丢弃跨不同集合组合变量的不变量。
- 最终,一个可比较集合包括了参与相关计算的变量。有几个例外情况:例如,在数组指针计算中,我们不会合并基元素和索引元素的集合,因为它们不是直接相关的。
-
- 每当不同的不变量具有重叠的条件时,通过重用先前计算的值来优化它们的运行时验证。
- 这一步针对Daikon在函数节点处枚举模板,如果函数中位操作就不用枚举。
- 特别地,我们针对共享某些变量上相同条件的一对可能不变量进行优化。
- 如果这两个不变量涉及两个程序点p,p0,其中p0只能在p之后执行,我们使用标准的敏感流分析来确定在p和p0之间是否存在任何涉及变量的中间重新定义。此时,我们只需传播在p处计算的值,从而节省在p0处的计算成本。
-
变量值范围分析和比较集计算会提前预处理,随后传递到不变量推断阶段。重叠条件将在生成程序时处理(即再程序中添加用于简化不变量的代码,这些代码将在测试过程中使用)
3.4 输入集选择
- 因程序动态不变量需要大量程序运行轨迹,所以与 evolutionary fuzzer 类似,初始输入集很关键
- 一个不明智的做法会 产生 不能很好描述在程序状态中变量的通用性的 不变量。
- 例如,一个常见的实例是在使用fuzzer测试解析器的时候会产生大量给定文件格式的文件,然而大部分是合法的文件格式。如果我们从这个语料库中进行不变量推断,我们会将我们的不变量偏移在有效地文件格式上,在一些情况下这是错误的,因为我们会错过与无效输入有关的程序状态的划分。
- 同时我们也想解决当fuzzer在覆盖上饱和时找bug不行的问题,我们的一个自然的想法是使用基于覆盖引导的fuzzer的生成输入队列作为程序动态不变量生成的语料库。在该语料库上违反不变量产生的新的输入,可以作为对fuzzer的新颖的反馈,同时缓解基于路径覆盖的饱和度
- 为了确认我们的想法,我们为在 $5中测试的程序下载了一个全为有效文件的数据集来生成不变量(即语料库全是好的,不变量会过拟合)。
- 我们随后将这些不变量与使用fuzzer运行24h后的输入队列作为语料库产生的不变量作比较。
- 试验显示,使用从过拟合的语料库中提取的不变量比从fuzzer输入队列提取的不变量,在我们的方法中,前者会比后者少发现20%的bug
4 实现
-
之前章节,我们介绍了动机和我们方法的关键思想。然而,我们有目的性的避免讨论了我们方法的两个重要的方面
-
- 我们如何定义我们想从不变量中捕获的状态
-
- 我们如何在被测试程序中插桩来收集我们技术需要的信息
-
-
我们的方法可以以不同的方式实现:
- 可以在目标源码上插桩,或在二进制上进行静态重写[20]或动态翻译[17],各种方法都有优缺点。
- 本研究选择基于编译的实现,使用LLVM[43]和DAIKON[25]在我们invariant-based fuzzing。
-
我们的原型是用C++编写的,并重新利用了Pereira等人[68]提出的用于LLVM的快速函数内整数范围分析,该分析需要渐近线性时间完成。
-
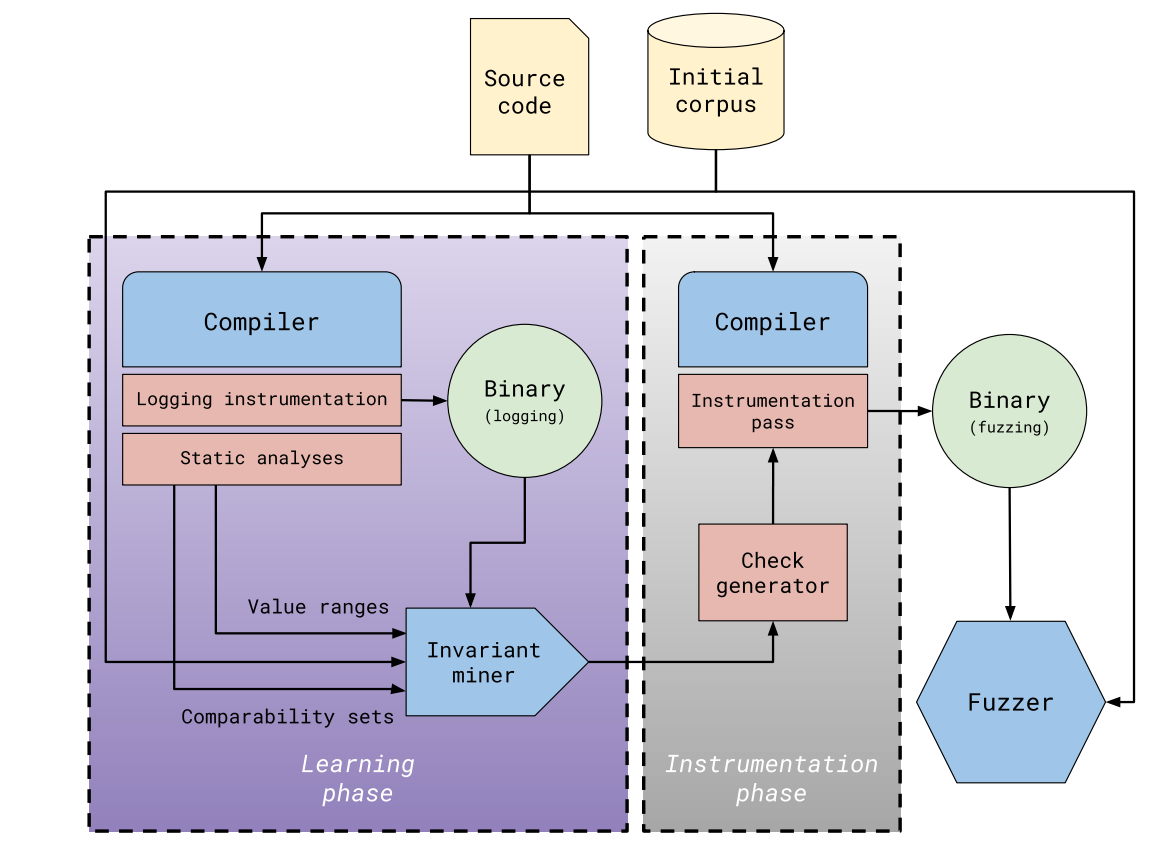
下图2展示了我们原型的结构图。我们为LLVM实现了两个自定义的编译转换阶段。
- 学习阶段:进行日志记录插桩,收集程序中变量状态,提供给不变量推断工具。
- 插桩阶段:增强被测试代码,使得不变量可以直接适配基于覆盖的fuzzer
-
学习阶段:
- 在输入语料库上执行增强版本的被测试程序,输入可有多种方式获得($3.4;$5中使用24小时的覆盖率引导模糊测试生成种子)
- 对于不变量挖掘,使用Daikon。 在每个插桩的位置,不变量挖掘的时间复杂度是变量数量的立方,然而由于我们的技术是在基本块级别上,变量数量为很小的常熟。
-
插桩阶段:
- 将推断的不变量信息编码到函数中来将它们暴露给 基于覆盖的模糊测试器。转换后的程序可以直接在任何基于AFL的模糊测试工具上运行。
4.1 状态不变量学习
-
原型实现在LLVM的IR上的好处:
- 因此容易在程序的基本块级别暴露程序状态。
- 此外,IR允许我们避免在源代码级别追踪复杂数据类型时出现未初始化值的问题[1]。
- Daikon的前端Kvasir使用耗费昂贵的动态二进制插桩[17]读取变量并检测内存。然而在IR上,我们可以我们只需等待地址在加载操作的结果中出现在虚拟寄存器中,然后将其用于追踪。
- 使用IR的另一个优点:在IR中,指令通常以单一静态赋值(SSA)形式表达[70]。SSA意味着每个变量只能被赋值一次,每个使用必须由一个(唯一的)先前定义到达。
-
SAA相关:
- 为了简便,我们忽略了浮点数指令,只对整数的SSA变量建模。
- 对于局部变量,由于在IR中一个源级变量可能存在多个SSA变量,我们将我们的分析限制在那些可以直接连接到源级变量的SSA变量上,通过使用来自LLVM前端的调试元数据。
- 当程序访问非局部存储或非原始类型的字段时,LLVM将作为当前内容的加载操作的结果引入一个SSA变量。通过对这种IR变量进行仪器化,我们的不变量挖掘也扩展到全局变量、堆存储和结构体的字段。
- 由于我们的目标不仅仅是对应用程序的状态进行建模,而是提高面向安全的测试技术的有效性,因此我们的分析重点在可能引起安全问题的变量上,根据以下三个规则:
- 该变量是GetElementPtr指令的一部分进行指针计算,除非仅涉及常量索引;
- 通过使用Load或Store指令将变量值从内存加载或存储;
- 该变量代表函数的返回值。
-
LLVM管道
- 我们实现了LLVM函数管道收集变量的值,同时完成对感兴趣变量的插桩,并完成了可比较集和值域分析[68]来进行不变量修建。
- 管道为每个代码模块创建json文件存储程序点和变量的信息(类型,比较集,范围)。随后将这些文件综合得到Daikon的declaration文件,随后依据比较集和范围提纯不变量(见$3.3)。
-
Daikon使用
- 我们指导Daikon在每个输入上运行插桩后程序,找到检测变量的值。
- 我们使用Daikon的即时使用模块挖掘不变量,其会从每个执行中依次学习不变量
4.2 程序插桩
略
5 评估
-
研究问题
- RQ1:我们的不变量删除是否有效地减少了不变量的数量?
- RQ2: 我们的反馈机制导致了状态爆炸吗?
- RQ3: 我们的反馈机制可以比单纯基于代码覆盖机制探索更多程序状态吗?
- RQ4: 我们的反馈机制可以比基于覆盖的揭示更多或不同的bug吗?
- RQ5: 我们的反馈机制引入的性能消耗如何?
-
基准程序
- 选择8个现实世界的目标程序,工作在不同类型文件上,同时我们为他们在解析阶段的实现使用了不同的策略
- 我们选择了包含bug且广泛应用于之前工作的版本[31,51,69]
- 我了更严密的评估,我们也人工增加了bug来评估bug发现能力。
- LAVA-M[22]基准不合适我们的方法,因为其包含的错误依赖magic-value ($6.2)比较[38]
- MAGMA [38] 基准也不合适,因为它们的硬编码日志记录原语(用于检查真实情况)分割了基本块,因此与我们的不变式构建和插装的粒度冲突。
- 表一展示了实验的程序。这里还展示了感知器,我们使用了AddressSanitizer (ASAN) 和 UndefinedBehaviourSanitizer (UBSAN) 编译时插装。然而,我们不得不为两个应用程序禁用 UBSAN,因为它引入了不想要的副作用,即使使用最简单的测试输入也会使它们崩溃。
- 选择8个现实世界的目标程序,工作在不同类型文件上,同时我们为他们在解析阶段的实现使用了不同的策略
-
试验设置
- 机器:x86_64,Intel® Xeon® Platinum 8260 CPU 2.4Ghz
- 使用AFL版本2.65d作为我们方法的参考fuzzer,随后与其他配置的AFL及进行比较
- 我们进行了5次实验减小fuzzing误差,使用中位数作为结果,每个实验48h的界限
- 从有效文件的初始组出发,我们使用AFL++运行24h获得种子队列作为初始输入,这即会用在提取不变量也会用在fuzzers的种子上。
- 剩余部分中,以下为我们的方法对比定义
- INVSCOV:使用基于不变量插桩的fuzzer
- CODECOV:使用经典代码覆盖的fuzzer
- CTXCOV:使用上下文敏感的增强代码覆盖的fuzzer
5.1 RQ1:InvariantPruning
- 计量最后产生的不变量数量对比
- 表2展示优化前后数量对比,共三个阶段:无优化,学习阶段优化,插桩阶段优化
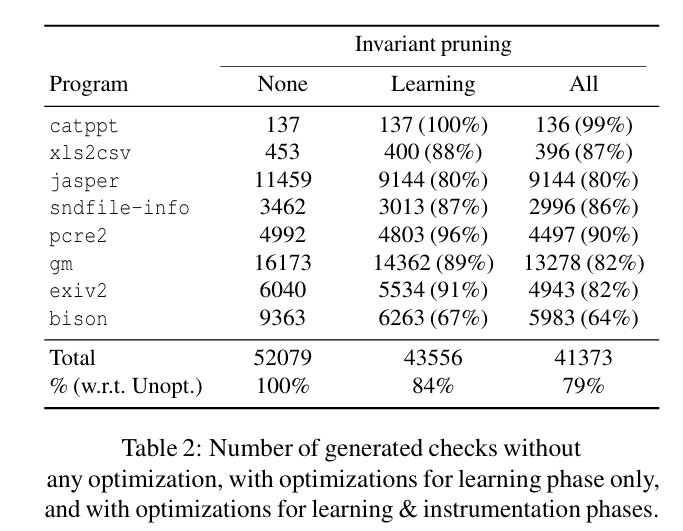
- 尽管看起来不变量数量优化较少,但确实可以增加fuzzer10%的运行效率
5.2 RQ2:StateExplosion
5.3 RQ3:Program State Exploration
5.4 RQ4:BugDetection
5.5 RQ5:Run-TimeOverhead
5.6 Discussion
- 我们的实验结果证实了我们的反馈,通过让变量与他们的“寻常值”不同,来提升fuzzer对只代码覆盖不能奖励到的程序状态的敏感度。
- 在65个程序bug点只有我们的方法可以触发的情况下,只进行代码覆盖只达到了43个,因为程序没有处在错误地状态。即使用了强化的代码覆盖反馈如上下文敏感,我们的方法也能发现更多bug。
- 我们的反馈机制产生的输入队列大小仅增长了62%,远小于内存反馈和一些基于代码的反馈。每个测试用例生成平均而言减缓了8%。这些代价可以被我们多发现的bug偿还。
- 与边缘覆盖相比,反馈机制在代码覆盖率方面不是递减的,在某些情况下,它还可以解锁更多的依赖于状态的程序部分以进行进一步探索。在综合场景中进行了简短的实验,发现INVSCOV和细粒度的代码反馈形式可以相互补充。这样的模糊器将能够更好地区分和探索那些受到控制流事实(例如调用路径)影响的状态属性。
6 其它相关工作
- 本节覆盖了安全相关的使用了不变量的作品,还有与我们方法相关的可以增强fuzzing效率的技术。
6.1 Invariants
- 不变量在历史上在许多发展的领域如软件测试,软件优化和维护[26]起到了关键的左右。在安全研究的上下文中,许多工作也探索了不变量在其它问题上的应用。
- 在畸形检测上下文中,不变量可以作为程序加固的oracle。例如[32,75]通过程序插桩阻止生产环境中的内存损坏利用,因为运行时检查的成本相对较低。Web应用程序也可以从类似的保护中受益,如[15]中使用DAIKON和PHPcode所探索的那样。
- 故障定位:当多个不变量被违反时,一个典型的根因定位的工作流程是研究相似的输入来过滤掉不相关的不变量。如[71],使用 dynamic backward slicing移除更多不变量。[7]对学习到的谓语进行统计学分析。
- 在$2.1中我们提到了将不变量作为规范在基于属性的测试中至关重要。QUICKCHECK [12]可能是这类系统中最著名的一个。最近的工作,如ZEST [59]和HYPOTHESIS [48],分别借鉴了模糊测试的概念,如反馈驱动的变异,以提高它们在测试Java和Python代码库时的效率。
6.2 模糊测试
-
Fuzz Testing(模糊测试)是学术界和工业界广泛关注的焦点,每年尝试改进其技术各个方面的工作数量呈爆炸式增长[50]。
-
我们认为,除了在$2.2节讨论的反馈进之外,fuzzer最重要的改进包括 绕过代码覆盖率障碍的技术,基于变异的程序路径执行以及捕捉静默错误。
- 幸运的是,这些进展和我们的方法是可以结合的。如5.3中利用AFL++的灵活性,我们已经将一些设计和我们的方法结合。
-
Roadblocks
-
Valid Inputs
-
Catching Silent Faults
-
HardTargets
7 限制和未来方向
- 我们的方法通过违反动态不变量来增强经典的基于代码覆盖的反馈。
- 由于我们为了兼容性而发出符合AFL的插桩,在更新覆盖范围时对共享映射进行索引时可能会出现哈希冲突——就像使用AFL一样。AFL++提供了一种无冲突但破坏兼容性的链接时间插桩方案[39]。我们可以设计一个从这种设计中受益的INVSCOV变体,并可能探索将不变和边缘反馈分开的映射
- 在方法学方面,我们的方法的一个内在限制是它不是自适应的。我们只学习一次不变量,而在探索过程中通过细化它们来探索新值条件是有可能的。因此,我们方法的后续工作将是设计一个在线不变量挖掘模块。最近的异常检测中的机器学习进展,如[16],可以为这一目标提供有效的支持。我们认为,一个能够自适应地学习变量上的状态空间划分的模糊器可以产生实际的影响,并可能有助于使OSS-Fuzz等饱和模糊测试活动捕获更多已经用CGF解决方案进行了充分测试的软件中的漏洞。
- 最后,由于我们在基本块级别研究数据事实,我们可能的不变量无法捕捉到在任何块中都不会一起处理的变量之间的“隐式”关系。
8 结论
- 使用可能的不变量作为fuzzers的反馈,以更好地抽象和探索程序状态。
- 过考虑控制程序状态的条件,可以发现一些潜在的漏洞,这些漏洞可能在很长时间内未被发现。
- 我们在不引发状态爆炸问题的情况下,实现了这一目标,并且性能开销适度,发现的漏洞数量增加。
- 希望这项工作可以为程序状态近似为模糊测试提供反馈的研究铺平道路,。
9 个人总结
- 本文使用程序动态不变量,强化了经典的基于代码覆盖的fuzzer,具体地对于fuzzer生成的违反不变量的输入,其会增加他的优先级。
- 本文中,不变量在代码块级别生成,同时也晒出了一些无用的不变量,这是我们需要学习的。
- 对debloating的思考:直接使用输入集覆盖的代码路径上的不变量作为规约,在程序简化时,简化后程序不能违背该规约,对于错误地简化可以提前发现。